Results & Discussion
1) Ecosystem Classifications (western North America)
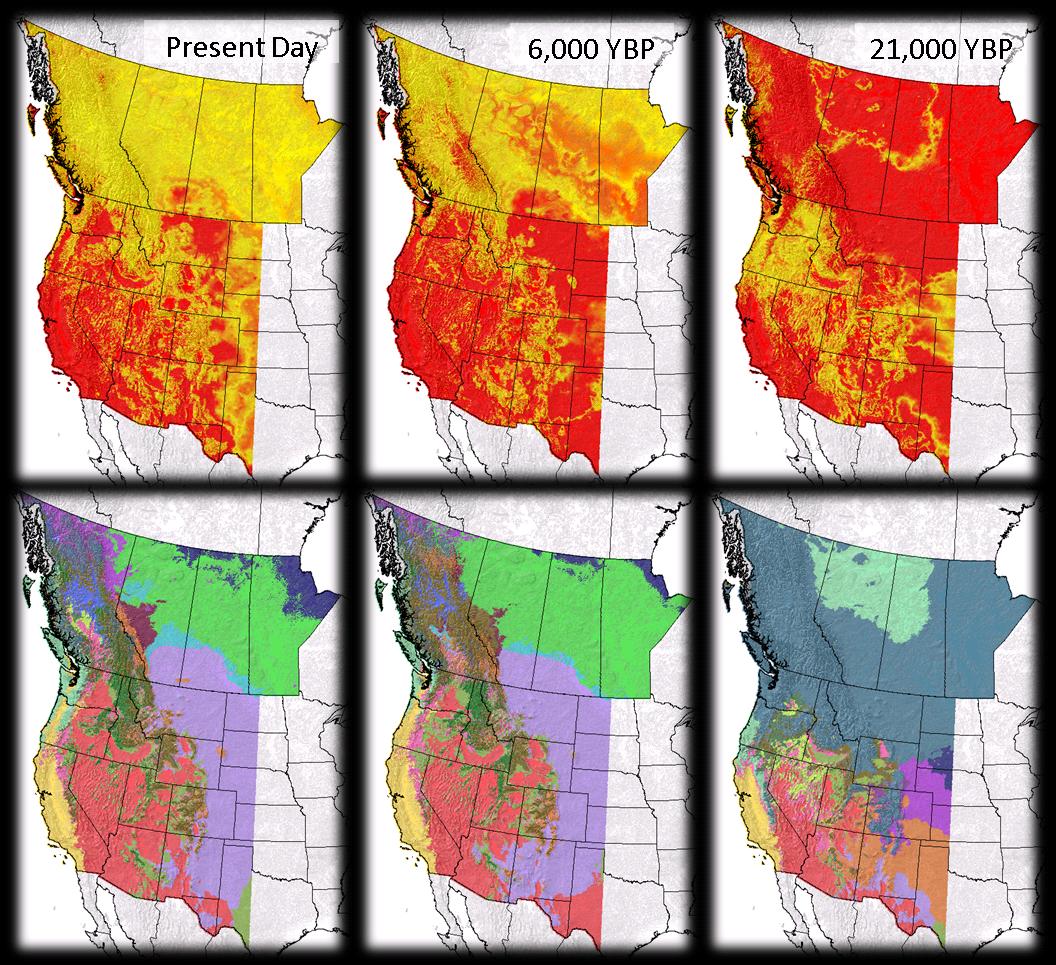
The discriminant analysis (DISCRIM) procedure discussed in 'Statistical Analysis' was used to generate ecosystem classifications for the the entire western North America study area for both the present climate data and for two periods of paleoclimate data: 6,000 and 21,000 YP.
To compare these classifications to the climate data of the time, you may view the compared mean annual temperature (MAT) and mean annual precipitation (MAP) of the three time periods here:
In both the above images, the colour legend has been kept consistent between time periods to allow for easy comparison of the climate changes. In the 21,000 YBP MAT image, there is no data shown for the northeastern portion of the study area. The temperature data for this area doesn't appear as it is beyond (negatively) the range of present-day temperature upon which the legend was applied. For a complete look at the 21,000 YBP temperature data, click here.
1) Ecosystem Classifications (Top)
.PNG) (Click for larger image) |
|
.PNG) (Click for larger image) |
|
|
|
.PNG)
A closer look at the southern extent of the study area shows minimal difference between the present-day and 6,000 YBP data, but a dramatic change in the 21,000 YBP period.
.PNG) (Click for larger image) |
|
.PNG) (Click for larger image) |
|
|
|
.PNG)
It is important to remember that the classification of paleo-ecosystems assumes an instantaneous migration by plants and trees and does not consider variations in succession order or post-ice migration rates. However, the large timescale of the data may negate any ‘migration latency effects’ that would affect ecosystem classification, especially given the rapid response of plants to climate changes that has been shown in past research (Williams et al. 2002). If there is an area of concern, I would assume that ecosystem classifications made at the periphery of continental ice sheets , where soils, etc. may not be fully developed, would be most affected by this phenomenon.
2) Probability and Confidence Maps (Top)
In addition to producing the new ecosystem classifications, the DISCRIM procedure also produces a classification 'probability' as part of the data output. This probability is essentially a classification confidence. It corresponds to the Mahalanobis distance from the assigned class and whether there are other classes in the same ranges that could potentially be correct. As with any probability, the higher the value, the more likely that the classification is appropriate. Because these probabilities are attached to spatial data, they can be mapped just like any other data variable. What is produced is a map of the study area showing the confidence levels that the DISCRIM procedure has applied to each data point. In the following images, the probability is mapped from red to yellow (red being highest probability/confidence and yellow being the lowest). For a single image comparison of all time periods, click here. In all images, the values range from zero (yellow) to 1 (red).
.PNG) (Click for larger image) |
|
.PNG) (Click for larger image) |
|
|
|
 When first viewed, I found these probabilities to be quite counterintuitive--almost the exact opposite of what I expected to see. I anticipated a high level of confidence in the baseline areas of Alberta and British Columbia, as these are the locations upon which the classification system was calibrated. I also expected to see very low probabilities in the far outlier locations (southern USA in the present-day and 6,000 YBP maps and the northern locations in the 21,000 YBP image). Instead, the probabilities are exactly the opposite. The DISCRIM procedure assigns the highest probabilities to the areas in which I would expect the data to be well outside of the baseline calibration data. While this seems paradoxical, an understanding of the DISCRIM procedure explains the phenomenon.
When first viewed, I found these probabilities to be quite counterintuitive--almost the exact opposite of what I expected to see. I anticipated a high level of confidence in the baseline areas of Alberta and British Columbia, as these are the locations upon which the classification system was calibrated. I also expected to see very low probabilities in the far outlier locations (southern USA in the present-day and 6,000 YBP maps and the northern locations in the 21,000 YBP image). Instead, the probabilities are exactly the opposite. The DISCRIM procedure assigns the highest probabilities to the areas in which I would expect the data to be well outside of the baseline calibration data. While this seems paradoxical, an understanding of the DISCRIM procedure explains the phenomenon.
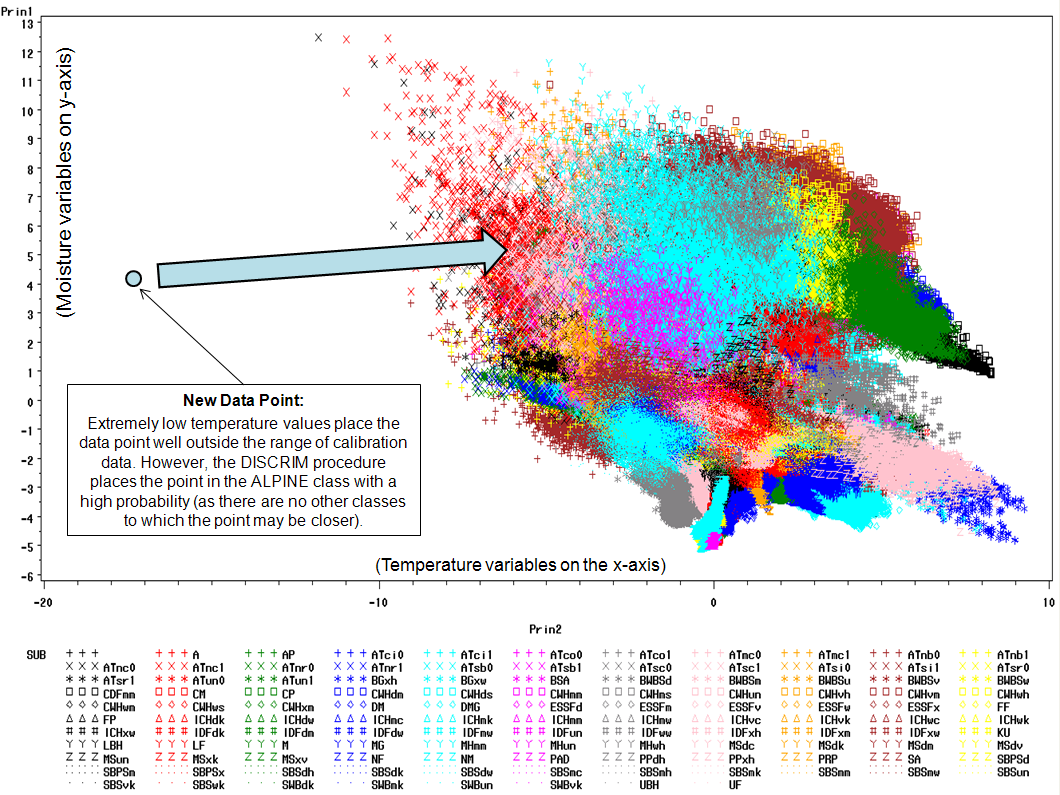
The discriminant analysis procedure assigns classes based on a new data point's distance from the centre-point of the nearest class from the calibration data (the baseline data). Hence, a new data point that falls well within the cluster of calibration points is bound to be reasonable close to a multitude of baseline classification centre-points--leaving a higher potential for a misclassification. Conversely, any outlier data, such as the far north points of the 21,000 YBP data set are outside the mass of baseline data, leaving them close to only whichever classification centre-point is at the edge of the baseline data (see figure on left for an illustration of this).
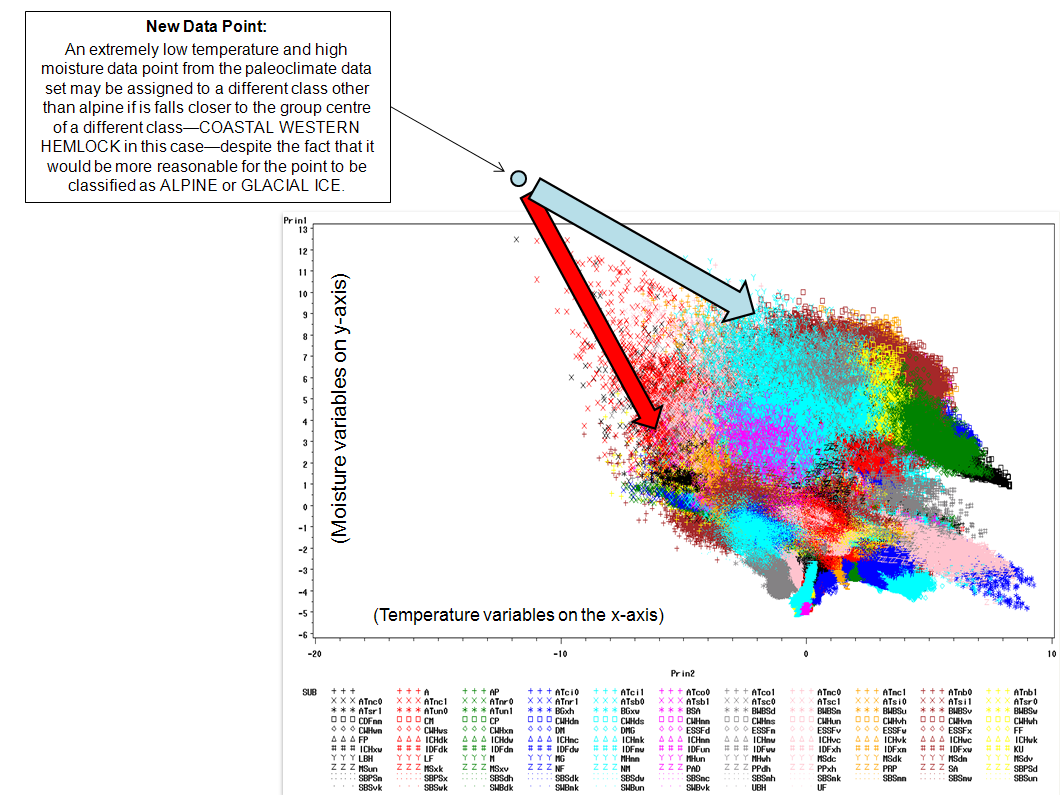
While the classification probability values produce a powerful visual image of the classification confidence, these figures can also be misleading. Remember, this is not a confidence in the actual ecosystem characteristics (plant communities, etc.). It is merely a probability that the DISCRIM procedure has placed a novel data point into the most appropriate class available to it. Because the analysis is constrained to the classifications provided in the calibration data (the baseline data in this case), it merely places novel data points into the best category available, regardless of how closely the new data matches the calibration data in that particular class. This is more easily explained in the following examples:
 (Click for larger image) |
|
 (Click for larger image) |
|
The assignment of ecosystem classifications to the extreme outlier climatic conditions (as is seen in the northern areas of the 21,000 YBP classification) with a very high probability represents a different but related problem to the classification probabilities. As discussed previously, because this range of climatic data (primarily extremely low temperatures) has no appropriate EQUAL among the modern baseline classifications, the discriminant analysis forces the areas into the closest available category—and does so with a very high level of confidence. This makes sense after looking at the principal component plots (see 'Statistical Analysis'). If a new climatic condition were to fall a great distance away from the plot, it could not be reasonably classified with the baseline ecosystem classifications that are available. However, this would not prevent the DISCRIM procedure from assigning it to an ecosystem class.
The mapped probability values become even more interesting when they are compared to the ecosystem classification maps to which they correspond:
 (Click for larger image) |
|
The next step in the classification procedure would be to establish some threshold values for classification distances, potentially linked to the probability. This is discussed further in 'Future Directions'.
<<<< Back to Statistical Analysis | Top of this page | Continue on to Future Directions
References:
Manly, B. F. J. (2005). Multivariate Statistical Methods: A Primer. 3rd Ed. Chapman & Hall / CRC Press, Boca Raton.
Williams, J. W., D. M. Post, et al. (2002). "Rapid and widespread vegetation responses to past climate change in the North Atlantic region." Geology 30(11): 971-974.
© 2007 - David Roberts, University of Alberta