Artificial Neural Networks trained online on a correlated stream of data suffer from
catastrophic interference.
We propose learning a representation that is robust to catastrophic interference.
To learn the representation, we propose MRCL, a second order meta-learning objective
that directly minimizes interference and maximizes forward transfer.
Highly sparse representations naturally emerge by minimizing our proposed objective.
Moreover, these representations are highly effective at reducing interference and forgetting
on continual learning benchmarks.
Motivation
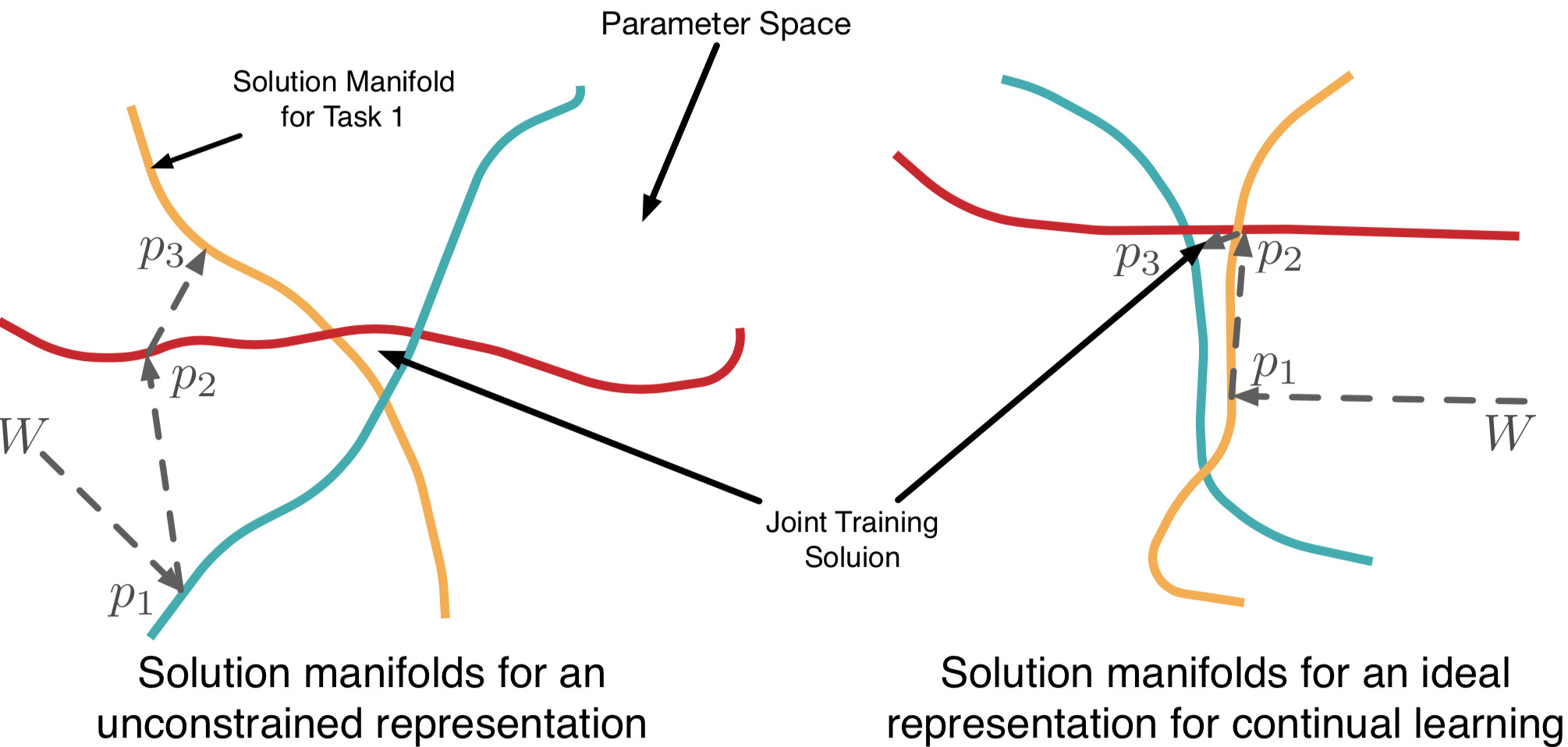
We hypothesize that in the observation space, gradient w.r.t one task interference with
other
tasks, and by learning a representation in which solution manifolds of different tasks are
either parallel or orthogonal, we can mitigate catastrophic interference as shown in Figure
1.
Figure 1 : We want to find a representation such that solution manifold of
different tasks are parallel or orthogonal.
More concretely, we propose transforming the input into R, a large d dimensional vector,
using a deep
Representation Learning Network (RLN) such that it is possible to learn without interference
from R. An example architecture of our method is shown in Figure 2.
To train RLN, we treat the parameters in the RLN as meta-parameters which are updated to
minimize interference when learning on correlated sequences of data using a Task Learning
Network (TLN).
Figure 2 : One possible realization of an architecture used by MRCL. RLN
learns to transform inputs into a space that allows learning without forgetting.
Results
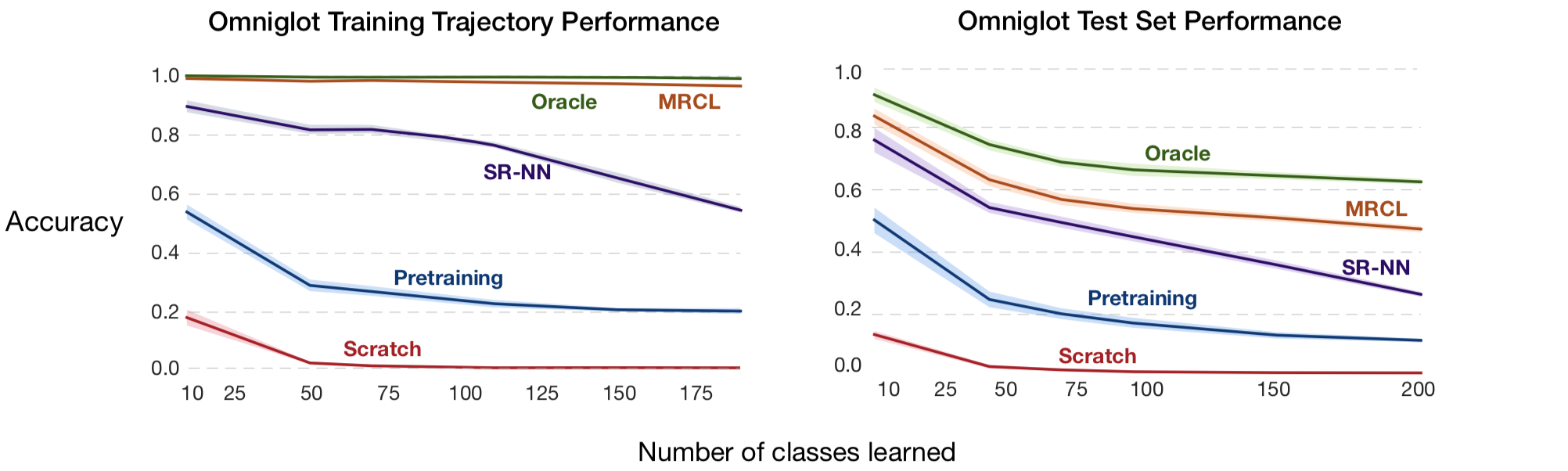
We compare MRCL with a Pretraining, a method that learns a representation by pre-training on the
meta-training dataset, and SR-NN, a recent method that learns sparse representations to minimize
interference. We report the results in Figure 3.
Figure 3 : Results of training a classifier incrementally (One class at a time)
at meta-test time.
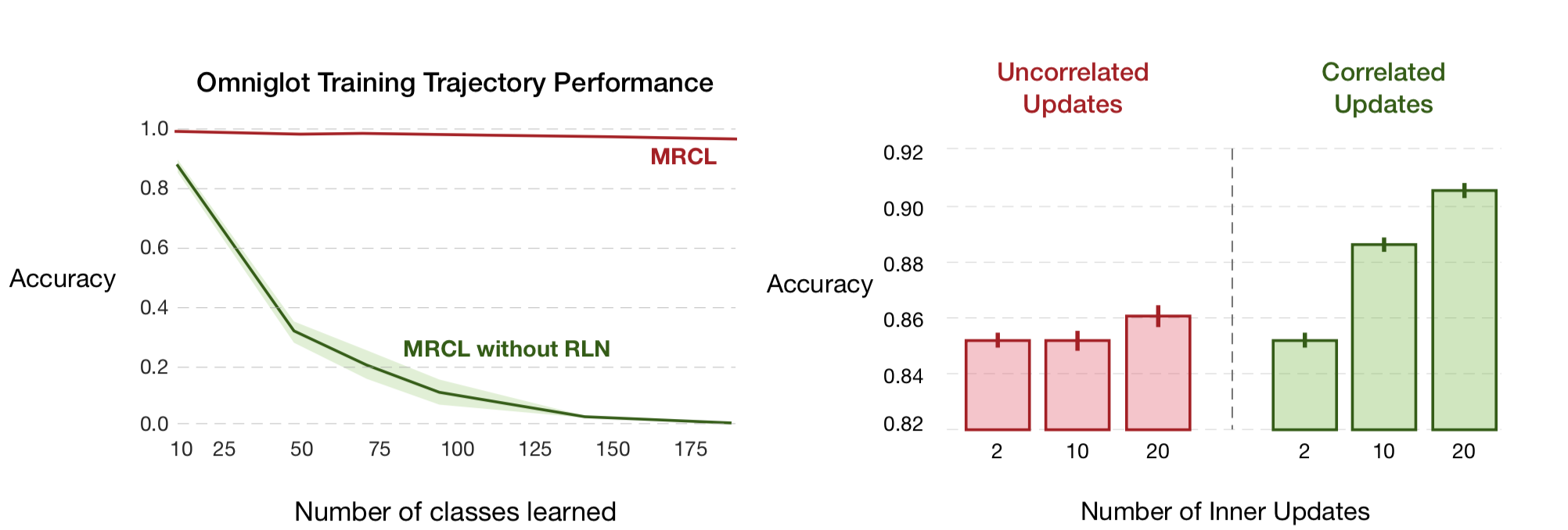
Ablation Studies
(Left) Meta-learning a network initialization (Similar to MAML) is not sufficient for
reducing interference.
(Right) Using longer correlated trajectories in the inner loop of meta-learning results in
better representations. Our hypothesize is that online updates using long correlated
trajectories result in more interference and provide a stronger training signal.