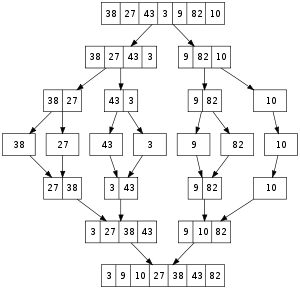
# Fibonacci example |
import sys |
|
def fib(n): |
if n == 0: return 1 |
if n == 1: return 1 |
return fib(n-1) + fib(n-2) |
|
# fetch n from the command line args |
if len(sys.argv) > 1: |
k = int(sys.argv[1]) |
else: |
k = 10 |
|
f = fib(k) |
print("Fib ", k, " is ", f) |
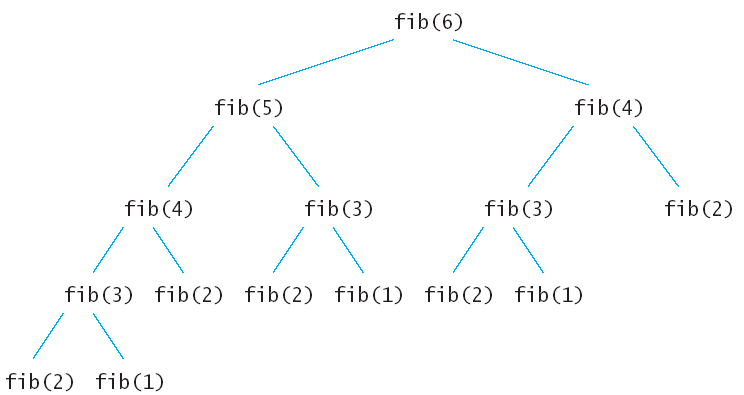
# Fibonacci example |
import sys |
|
def fib(n): |
global call_count |
call_count += 1 |
if n == 0: return 1 |
if n == 1: return 1 |
return fib(n-1) + fib(n-2) |
|
if len(sys.argv) > 1: |
k = int(sys.argv[1]) |
else: |
k = 10 |
|
call_count = 0 |
f = fib(k) |
print("Fib ", k, " is ", f, " work ", call_count); |
# Fibonacci example, with memoization |
import sys |
|
# Fibonacci is defined as: fib(n) = fib(n-1) + f(n-2), where |
# fib(0) = 1, fib(1) = 1 (or any other acceptable initial conditions) |
|
# when we compute fib, there is considerable overlap between the recursive |
# sub-problems. So this is not a divide and conquer where the sub-problems |
# are independent. So it makes sense to keep track of prior solutions of |
# sub-problems. |
|
# Alternatively, we can do the computation forward, since we can write |
# fib(n+2) = fib(n+1) + fib(n) |
# and in this case need only store the "frontier" of the last 2 values. |
|
# remember previously computed values of fib, including the base cases |
fib_at= { 0: 1, 1: 1 } |
|
def fib(n): |
global call_count |
global fib_at |
|
# have we computed fib(n) already? |
if n in fib_at: return fib_at[n] |
|
# no, so count this work |
call_count += 1 |
|
f = fib(n-1) + fib(n-2) |
fib_at[n] = f |
return f |
|
if len(sys.argv) > 1: |
k = int(sys.argv[1]) |
else: |
k = 10 |
|
call_count = 0 |
f = fib(k) |
print("Fib ", k, " is ", f, " work ", call_count); |
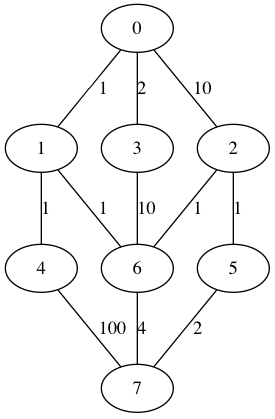
A[i, i] = 0 for 0 <= i < nAll entries are non-negative (>= 0), and and entry is infinity if there is no edge.
A[i, j] = the cost of the edge from i to j
0 1 10 2 N N N N |
1 0 N N 1 N N N |
10 N 0 N N 1 2 N |
2 N N 0 N N 10 N |
N 1 N N 0 N 1 100 |
N N 1 N N 0 N 2 |
N N 2 10 1 N 0 4 |
N N N N 100 2 4 0 |
Cost_k[i, j] = minimum cost of a path of k or less edges from i to jThen we showed how we can extend a solution for k to a solution with one more edge by observing that the minimum cost path of length k+1 or less from vertex s to vertex d is either one of length k or less, or is one of length k+1 that is found by exploring one more edge along a minimum cost path of length k. That is,
Cost_(k+1)[s, d] = min over i { Cost_k[s, i] + A[i, d] }where we observe that A[i,i] = 0 so that paths of length k or less are also considered.
Cost_(k+1) = Cost_k x A = A^kwhere the 'x' operation is the (min, +) vector dot product. That is, do a pairwise add of the elements and then select the min. Of we can compute Cost_n then we have the min cost of a path between any pair of vertices.
[(0, 1), (1, 4), (4, 3)]which is a path of 3 edges from 0 to 3.
Path_1[i, i] = [ ]You need to define Path_(k+1) for the remaining case.
Path_1[i, j] = [ (i, j) ] if A[i,j] != Infinity
Path_1[i, j] = None if A[i,j] == Infinity
Path_(k+1)[i, j] = Path_k[i, j] if Cost_(k+1)[i, j] = Cost_k[i, j]
| 21. Dynamic Programming Tangible Computing / Version 3.20 2013-03-25 |