Table 1 show the segment profiles for the different event types with and without applying the fiducial cuts. For the segment profiles the way in which the percentages in each segment class are calculated is different from that explained in section 4.4.1. In this case, the percentages in each segment class were obtained by counting up the number of segments in each class, dividing by the total number of segments in all classes, and multiplying by 100. It can be seen that most of the segments in an event are of the nasty class. This is particularly true in BG events for which only 2% of the segments are within our fiducial cuts. Few segments are split. This can be understood since the definition of a segment can only vary between four and eight hits, while five hits on a single-cell segment is the average. The number of spurious segments are high when no fiducial cuts are applied. These segments could be a problem in over estimating the track multiplicity at the track finding stage.
Table 2 shows the results of comparing the first and last MC ID's on each found segment. A good ID match represents cases in which the MC ID's of the first and last points are identical, while bad means they are not identical, and ambiguous\ means they are the same but of opposite sign.
Table 10 shows the percentage of found segments
within the fiducial cuts.
In the following the definition of percentage is the number
of segments under consideration times 100 divided by the
total number of segments, where the total number of segments
is the number of found plus the number of lost segments
within the fiducial cuts.
The normal algorithm is the proposed SLT segment
finding algorithm described in this note, while the
minimal algorithm and the truth algorithm were
described in section 4.4.
A segment finding efficiency greater than 92% is obtained
in the fiducial space.
The difference between the first and second rows in
table 10 show that a large fraction
( 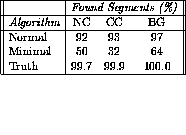 ) of the segments found in each event
type are above what could easily be found by the simplest
method.
This justifies the more complicated approach and extra
time spend in the present algorithm.
Approximately 10% of the segments were classified as
spurious, and the number of split segments was less than
0.1% for each event type and algorithm.
This is because of the small number of points (four)
required to define a segment.
The different percentages of found segments in the
different event types for the minimum algorithm reflects
the relative density of hits in the different event types.
The differences in the percentages of found segments from
100% by the truth algorithm indicates that our approach to
choosing the ambiguous direction of the segment fails less
than 0.3% of the time in the fiducial space.
) of the segments found in each event
type are above what could easily be found by the simplest
method.
This justifies the more complicated approach and extra
time spend in the present algorithm.
Approximately 10% of the segments were classified as
spurious, and the number of split segments was less than
0.1% for each event type and algorithm.
This is because of the small number of points (four)
required to define a segment.
The different percentages of found segments in the
different event types for the minimum algorithm reflects
the relative density of hits in the different event types.
The differences in the percentages of found segments from
100% by the truth algorithm indicates that our approach to
choosing the ambiguous direction of the segment fails less
than 0.3% of the time in the fiducial space.
![]()
Table: Efficiency for finding segments: ![]() GeV/c and
GeV/c and 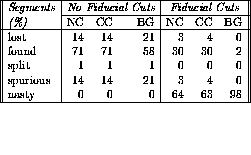 .
.
Table 11 show the percentage of nasty segments in the
different event types.
These numbers clearly reflect the effect of the fiducial
cuts on the different event types.
The contamination of segments within the fiducial cuts by
the large number of nasty segments ( ![]() % in NC and
CC events) could cause lost segments and possible lead to a
low track finding efficiency
% in NC and
CC events) could cause lost segments and possible lead to a
low track finding efficiency![]() .
.
![]()
Table: Nasty segments: ![]() GeV/c and
.
GeV/c and
.
Table 5 shows the efficiency for finding segments when no fiducial cuts are applied. Presumably the lost segments outside the fiducial space are largely due to the heavy hit masks in superlayer one. The above studies indicate that the segment finder must find the segments within fiducial space among a huge background of segments, and hits, outside the fiducial space.
![]()
Table 5: Efficiency for finding segments: no
fiducial cuts.
A study of the segment finding efficiency in the different
superlayers was performed.![]() For BG events the percentage of found segments was
approximately constant in each superlayer, while for NC and
CC events there was a slight decrease in efficiency in
superlayer one (
For BG events the percentage of found segments was
approximately constant in each superlayer, while for NC and
CC events there was a slight decrease in efficiency in
superlayer one (  ).
Figure 5 shows the percentage of nasty segments in
each superlayer for the different event types.
The flat distribution for BG events is due to low
).
Figure 5 shows the percentage of nasty segments in
each superlayer for the different event types.
The flat distribution for BG events is due to low ![]() tracks distributed approximately uniformly over the chamber.
The large number of nasty segments in superlayer one for
NC and CC events is due to low
tracks distributed approximately uniformly over the chamber.
The large number of nasty segments in superlayer one for
NC and CC events is due to low ![]() events giving low
angle tracks from the current jet.
events giving low
angle tracks from the current jet.
![]()
Figure 5: Percentage of segments which are in
the nasty class in each superlayer.
The segment finding efficiency in different geometrical
regions of the chamber and for different track ![]() \
was studied.
Different
\
was studied.
Different ![]() points were chosen at the fourth
wire at the forward end of the CTD in each axial superlayer.
For NC events the segment finding efficiency is relatively
uniform over
points were chosen at the fourth
wire at the forward end of the CTD in each axial superlayer.
For NC events the segment finding efficiency is relatively
uniform over ![]() for different values of minimum
for different values of minimum
![]() cut; table 6 shows the mean percentage of
segments found for different minimum
cut; table 6 shows the mean percentage of
segments found for different minimum ![]() cuts.
For BG events the distribution of the percentage of found
segments is uniform in
cuts.
For BG events the distribution of the percentage of found
segments is uniform in ![]() and raises slightly
for the case when
and raises slightly
for the case when ![]() is greater than 1.0 GeV/c.
The percentage of nasty segments raises with
is greater than 1.0 GeV/c.
The percentage of nasty segments raises with ![]() cut and
cut and
![]() cut as expected, but is relatively flat for
cut as expected, but is relatively flat for
![]() greater than 0.5 GeV/c and particularly so for BG
events.
greater than 0.5 GeV/c and particularly so for BG
events.

Table 6: Mean segment finding efficiencies for
different ![]() cuts.
cuts.
The minimum number of hits required to define a segment was varied (see figure 6). The efficiency for segment finding falls rapidly above a four hit definition for both NC and BG events, while the number of nasty segments is constant.
![]()
Figure 6: Segment finding efficiency for
different segment minimum hit definitions.
A study of the maximum number of hits required to define a mask shows that we must require more than eight for good NC efficiency. The efficiency for finding segments for BG events and the number of nasty segments is independent of this requirement.
