The RIFF reader/writer (UMSRiffReadWrite) object provides methods to access, read, write, and parse files in the RIFF format. Sample programs for reading and writing RIFF files are located in the UMS install directory.
To learn more about UMSRiffReadWrite, see:
For additional information on the structure of the RIFF file, see:
For introductory information, see Programming with Formatted File Access Objects.
RIFF is a standard file format used for storing Ultimedia Services files. RIFF enables audio, image, animation, and other Ultimedia Services elements to be stored in a common format. RIFF is also used as the basis for defining new file formats for Microsoft and OS/2 multimedia software.
The UMSRiffReadWrite object provides methods to locate, create, enter, exit, and access the RIFF chunk--the basic building block of a RIFF file. You can open, read from, and write to RIFF files the same way as other file types. Blocks of data are identified by tags. An advantage of tagged file formats is that an application can process blocks that it understands while ignoring blocks that do not concern it. RIFF can also be expanded upon (by adding new tags) without breaking existing applications.
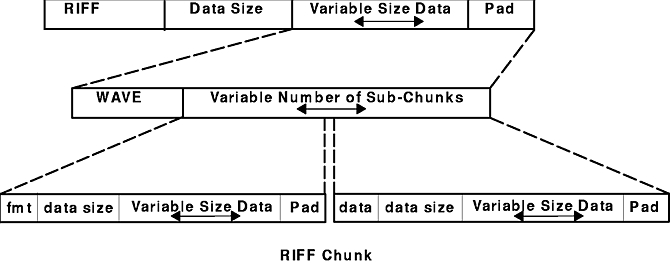
As illustrated in the diagram, a RIFF chunk begins with a chunk ID, which is a 4-character code (FOURCC) that identifies the representation of the chunk data. A program reading a RIFF file can skip over any chunk whose chunk ID it does not recognize. The chunk ID is followed by a 4-character chunk size (DWORD) specifying the size of the data field in the chunk. The data field containing the actual data of the chunk follows the 4-character chunk size. If the chunk ID is RIFF, the first four characters of the data portion of the chunk are a form type; if the chunk ID is LIST, the four characters are a list type.
The only chunks allowed to contain other chunks (subchunks) are those with a chunk ID of RIFF or LIST. The first chunk in a RIFF file must be a RIFF chunk. All other chunks in the file are subchunks of the RIFF chunk.
RIFF chunks include an additional field in the first 4 bytes of the data field. This additional field provides the form type of the field, which is a 4-character code identifying the format of the data stored in the file. A RIFF form is simply a chunk with a chunk ID of RIFF. For example, WAVE files have a form type of WAVE.
A LIST chunk contains a list, or ordered sequence, of subchunks. LIST chunks also include an additional field in the first 4 bytes of the data field. This additional field contains the list type of the field, which is a 4-character code identifying the contents of the list. For example, a LIST chunk with a list type of INFO can contain ICOP and ICRD chunks providing copyright and creation date information, respectively.
If an application recognizes the list type, it should know how to interpret the sequence of subchunks. However, since a LIST chunk can contain only subchunks (after the list type), an application that does not know about a specific list type can still navigate through the sequence of subchunks.
The following UMSRiffReadWrite method calls enable you to manage RIFF files:
A 4-character code is a 32-bit quantity representing a sequence of one to four ASCII alphanumeric characters, padded on the right with blank characters. The data type for a 4-character code is riff_fourcc.
To convert a null-terminated string into a 4-character code, use the string_to_fourcc method.
Use the create_chunk method to create a new chunk by writing a chunk header at the current position in an open file.
To create a chunk, specify the riff_fourcc chunk type and an estimated size of the chunk. The actual size of the chunk is set to the amount of data actually written following an ascend out of the chunk. If you specify a chunk type of RIFF or LIST, you must also specify the type of RIFF or LIST chunk to be created.
After you create a new chunk, the file position is set to the data field of the chunk (8 bytes from the beginning of the chunk). If the chunk is a RIFF or LIST chunk, the file position is set to the location following the form type or list type (12 bytes from the beginning of the chunk). The advisory_size is assumed to be a proposed chunk size; if it turns out to be correct (if you write that much data into the chunk before calling the ascend method to end the chunk), ascend does not have to seek back and correct the chunk header.
RIFF files can consist of nested chunks of information. The UMSRiffReadWrite object includes two methods you can use to move between chunks in a RIFF file: ascend and descend. You might think of these functions as high-level seek functions. When you descend into a chunk, the file position is set to the data field of the chunk (8 bytes from the beginning of the chunk). For RIFF and LIST chunks, the file position is set to the location following the form type or list type (12 bytes from the beginning of the chunk). When you ascend out of a chunk, the file position is set to the location following the end of the chunk.
The descend method descends into a chunk or searches for a chunk, beginning at the current file position. The descend method descends into the next RIFF chunk that matches the specified riff_fourcc type. If this type is 0, the method descends into the chunk at the current file position. This method also requires the current file position to be at the start of a chunk.
After you descend into a chunk and read the data in the chunk, you can move the file position (pointer) to the beginning of the next chunk. This is accomplished by ascending out of the chunk using the ascend method. The method ascends to the location following the end of this chunk.
If the chunk was created and descended into using create_chunk, the current file position is assumed to mark the end of the data portion of the chunk. If the chunk size is not the same as the value that was specified in the advisory position in create_chunk, the ascend method seeks back and corrects the chunk size in the chunk header before ascending from the chunk. Also, if the chunk size is an odd number, the ascend method writes a null pad byte at the end of the chunk.
A RIFF file which contains WAVE audio data is organized as follows:
a RIFF file
size=94252
RIFF type is WAVE
{
chunk type is fmt
chunk size=16 roundsize=16
{
fmt
}
chunk type is data
chunk size=94215 roundsize=94216
{
data
}
}
The following are pseudocode examples that illustrate steps required to read, write, and create a RIFF chunk. The function names are for illustration purposes only and are not actual method names within the UMSRiffReadWrite object. The following example illustrates how to navigate through the RIFF chunks:
open(...,O_RDONLY,...)
Descend() Descend into RIFF "WAVE" chunk.
GetCurrentChunkInfo() Get riff header info.
Descend() Descend into "fmt " chunk.
GetCurrentChunkInfo() Get "fmt " chunk size.
read() Read chunk data.
Ascend() Ascend from "fmt " chunk.
Descend() Descend into "data" chunk.
GetCurrentChunkInfo() Get "data" chunk size.
read() Read chunk data.
read() Read chunk data.
read() Read chunk data.
Ascend() Ascend from "data" chunk.
Descend() Fail: end of RIFF "WAVE" chunk.
Ascend() Ascend from RIFF "WAVE" chunk.
Descend() Fail: end of RIFF file.
close()
To write a WAVE file of a similar format, the file must be organized into chunks of data. Each chunk type is identified by a FOURCC identifier. Chunks are written to the file along with their corresponding data. For example:
open(...,O_WRONLY,...)
CreateChunk() Create and descend into RIFF "WAVE" chunk.
CreateChunk() Create and descend into "fmt " chunk.
write() Write chunk data.
Ascend() Ascend from "fmt " chunk.
CreateChunk() Create and descend into "data" chunk.
write() Write chunk data.
write() Write chunk data.
write() Write chunk data.
write() Write chunk data.
Ascend() Ascend from "data" chunk.
Ascend() Ascend from RIFF "WAVE" chunk.
close()
UMSRiffReadWrite object method calls include:
For introductory information, see Programming with Formatted File Access Objects.
{kind=link}