The following information provides an overview of the threads library and introduces major programming concepts for multi-threaded programming. Unless otherwise specified, the threads library always operates within a single process.
Read the following to learn more about programming with threads:
Basic thread operations include thread creation and termination.
Thread creation differs from process creation in that no parent-child relation exists between threads. All threads, except the initial thread automatically created when a process is created, are on the same hierarchical level. A thread does not maintain a list of created threads, nor does it know the thread that created it.
When creating a thread, an entry-point routine and an argument must be specified. Every thread has an entry-point routine with one argument. The same entry-point routine may be used by several threads. See Creating Threads for more information about thread creation.
Threads can terminate themselves by either returning from their entry-point routine or calling a library subroutine. Threads can also terminate other threads, using a mechanism called cancellation. Any thread can request the cancellation of another thread. Each thread controls whether it may be canceled or not. Cleanup handlers may also be registered to perform operations when a cancellation request is acted upon. See Terminating Threads for more information about thread termination.
Threads need to synchronize their activities to effectively interact. This includes:
The threads library provides three synchronization mechanisms: mutexes, condition variables, and joins. These are primitive but powerful mechanisms, which can be used to build more complex mechanisms.
Mutual exclusion locks (mutexes) can prevent data inconsistencies due to race conditions. A race condition often occurs when two or more threads need to perform operations on the same memory area, but the results of computations depends on the order in which these operations are performed.
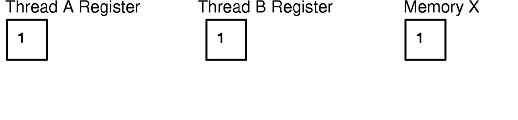
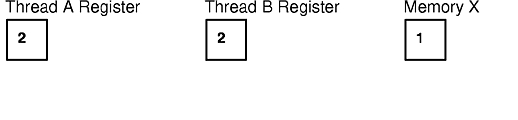
Consider, for example, a single counter, X, that is incremented by two threads, A and B. If X is originally 1, then by the time threads A and B increment the counter, X should be 3. Both threads are independent entities and have no synchronization between them. Although the C statement X++ looks simple enough to be atomic, the generated assembly code may not be, as shown in the following pseudo-assembler code:
move X, REG inc REG move REG, X
If both threads are executed concurrently on two CPUs, or if the scheduling makes the threads alternatively execute on each instruction, the following steps may occur:
Note that in most cases thread A and thread B will execute the three instructions one after the other, and the result would be 3, as expected. Race conditions are usually difficult to discover, because they occur intermittently.
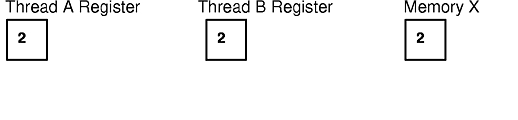
To avoid this race condition, each thread should lock the data before accessing the counter and updating memory X. For example, if thread A takes a lock and updates the counter, it leaves memory X with a value of 2. Once thread A releases the lock, thread B takes the lock and updates the counter, taking 2 as its initial value for X and incrementing it to 3, the expected result.
See Using Mutexes for more information about mutexes.
Condition variables allow threads to block until some event or condition has occurred. Boolean predicates indicate whether the program has satisfied a condition variable. The complexity of a condition variable predicate is defined by the programmer. A condition can be signaled by any thread to either one or all waiting threads. See Using Condition Variables to get more information.
When a thread is terminated, its storage may not be reclaimed, depending on an attribute of the thread. Such threads can be joined by other threads and return information to them. A thread that wants to join another thread is blocked until the target thread terminates. This joint mechanism is a specific case of condition-variable usage, the condition is the thread termination. See Joining Threads for more information about joins.
The threads library allows the programmer to control the execution scheduling of the threads. The control is performed in different ways:
The two last types of controls are known as synchronization scheduling.
A thread has three scheduling parameters:
The scheduling parameters can be set before the thread's creation or during the thread's execution. In general, controlling the scheduling parameters of threads is important only for threads that are compute-intensive. Thus the threads library provides default values that are sufficient for most cases. See Threads Scheduling for more information about controlling the scheduling parameters of threads.
Synchronization scheduling is a complex topic. Some implementations of the threads library do not provide this facility.
Synchronization scheduling defines how the execution scheduling, especially the priority, of a thread is modified by holding a mutex. This allows custom-defined behavior and avoids priority inversions. It is useful when using complex locking schemes. See Synchronization Scheduling for more information.
The threads library provides other useful facilities to help programmers implement powerful functions. It also manages the interactions between threads and processes.
The threads library provides an API for handling synchronization and scheduling of threads. It also provides facilities for the following purposes:
Threads and processes interact when handling specific actions:
This section provides some general comments about the threads library API. The following information is not required for writing multi-threaded programs, but may help the programmer understand the threads library API.
The threads library API provides an object-oriented interface. The programmer manipulates opaque objects using pointers or other universal identifiers. This ensures the portability of multi-threaded programs between systems that implement the threads library. It also allows implementation changes between two releases of AIX that necessitate only programs to be re-compiled. Although some definitions of data types may be found in the threads library header file (pthread.h), programs should not rely on these implementation-dependent definitions to directly handle the contents of structures. The regular threads library subroutines must always be used to manipulate the objects.
The threads library essentially uses three kinds of objects (opaque data types): threads, mutexes, and condition variables. These objects have attributes which specify the object properties. When creating an object, the attributes must be specified. In the threads library, these creation attributes are themselves objects, called attributes objects.
Therefore, there are three pairs of objects manipulated by the threads library:
Creating an object requires the creation of an attributes object. An attributes object is created with attributes having default values. Attributes can then be individually modified using subroutines. This ensures that a multi-threaded program will not be affected by the introduction of new attributes or changes in the implementation of an attribute. An attributes object can thus be used to create one or several objects, and then destroyed without affecting objects created with the attributes object.
Using an attributes object also allows the use of object classes. One attributes object may be defined for each object class. Creating an instance of an object class would be done by creating the object using the class attributes object.
The identifiers used by the threads library follow a strict naming convention. All identifiers of the threads library begin with pthread_. User programs should not use this prefix for private identifiers. This prefix is followed by a component name. The following components are defined in the threads library:
Data types identifiers end with _t. Subroutines and macros end with an _ (underscore), followed by a name identifying the action performed by the subroutine or the macro. For example, pthread_attr_init is a threads library identifier (pthread_) concerning thread attributes objects (attr) and is an initialization subroutine (_init).
Explicit macro identifiers are in uppercase letters. Some subroutines may, however, be implemented as macros, although their names are in lowercase letters.
Writing Reentrant and Thread-Safe Code
{kind=link}
{kind=link}
{kind=link}