NFS allows programs on one system to access files on another system transparently by mounting the remote directory. Normally, when the server is booted, directories are made available by the exportfs command, and the daemons to handle remote access (nfsds) are started. Similarly, the mounts of the remote directories and the initiation of the appropriate numbers of biods to handle remote access are performed during client system boot.
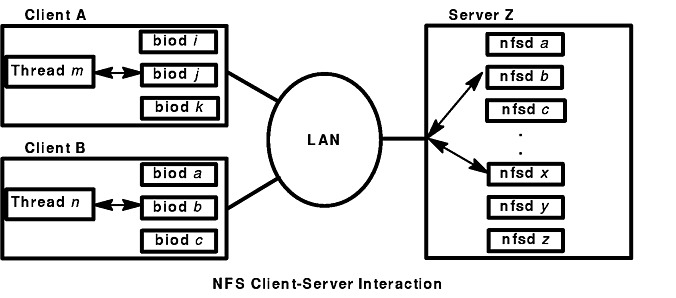
The figure"NFS Client-Server Interaction" illustrates the structure of the dialog between NFS clients and a server. When a thread in a client system attempts to read or write a file in an NFS-mounted directory, the request is redirected from the normal I/O mechanism to one of the client's NFS block I/O daemons (biods). The biod sends the request to the appropriate server, where it is assigned to one of the server's NFS daemons (nfsds). While that request is being processed, neither the biod nor the nfsd involved do any other work.
Because biods and nfsds handle one request at a time, and because NFS response time is often the largest component of overall response time, it is undesirable to have threads blocked for lack of a biod or nfsd. The general considerations for configuring NFS daemons are:
Determining the best numbers of nfsds and biods is an iterative process. Rules of thumb can give you no more than a reasonable starting point.
By default there are six biods on a client and eight nfsds on a server. The defaults are a good starting point for small systems, but should probably be increased for client systems with more than two users or servers with more than 2 clients. A few guidelines are:
After you have arrived at an initial number of biods and nfsds, or have changed one or the other:
The numbers of nfsds and biods are changed with the chnfs command. To change the number of nfsds on a server to 10, both immediately and at each subsequent system boot, you would use:
# chnfs -n 10
To change the number of biods on a client to 8 temporarily, with no permanent change (that is, the change happens now but is lost at the next system boot), you would use:
# chnfs -N -b 8
To change both the number of biods and the number of nfsds on a system to 9, with the change delayed until the next system boot (that is, the next IPL), you would use:
# chnfs -I -b 9 -n 9
In extreme cases of a client overrunning the server, it may be necessary to reduce the client to one biod. This can be done with:
# stopsrc -s biod
This leaves the client with the kproc biod still running.
One of the choices you make when configuring NFS-mounted directories is whether the mounts will be hard or soft. When, after a successful mount, an access to a soft-mounted directory encounters an error (typically, a timeout), the error is immediately reported to the program that requested the remote access. When an access to a hard-mounted directory encounters an error, NFS retries the operation.
A persistent error accessing a hard-mounted directory can escalate into a perceived performance problem because the default number of retries (1000) and the default timeout value (.7 second), combined with an algorithm that increases the timeout value for successive retries, mean that NFS will try practically forever (subjectively) to complete the operation.
It is technically possible to reduce the number of retries, or increase the timeout value, or both, using options of the mount command. Unfortunately, changing these values sufficiently to remove the perceived performance problem might lead to unnecessary reported hard errors. Instead, hard-mounted directories should be mounted with the intr option, which allows the user to interrupt from the keyboard a process that is in a retry loop.
Although soft-mounting the directories would cause the error to be detected sooner, it runs a serious risk of data corruption. In general, read/write directories should be hard mounted.
Related to the hard-versus-soft mount question is the question of the appropriate timeout duration for a given network configuration. If the server is heavily loaded, is separated from the client by one or more bridges or gateways, or is connected to the client by a WAN, the default timeout criterion may be unrealistic. If so, both server and client will be burdened with unnecessary retransmits. For example, if
$ nfsstat -cr
reports a significant number (> 5% of the total) of both timeouts and badxids, you could increase the timeo parameter with:
# smit chnfsmnt
Identify the directory you want to change, and enter a new value on the line "NFS TIMEOUT. In tenths of a second." For LAN-to-LAN traffic via a bridge, try 50 (tenths of seconds). For WAN connections, try 200. Check the NFS statistics again after at least one day. If they still indicate excessive retransmits, increase timeo by 50% and try again. You will also want to look at the server workload and the loads on the intervening bridges and gateways to see if any element is being saturated by other traffic.
NFS maintains a cache on each client system of the attributes of recently accessed directories and files. Five parameters that can be set in the /etc/filesystems file control how long a given entry is kept in the cache. They are:
Each time the file or directory is updated, its removal is postponed for at least acregmin or acdirmin seconds. If this is the second or subsequent update, the entry is kept at least as long as the interval between the last two updates, but not more than acregmax or acdirmax seconds.
If your workload does not use the NFS ACL support on a mounted file system, you can reduce the workload on both client and server to some extent by specifying:
options = noacl
as part of the client's /etc/filesystems stanza for that file system.
NFS does not have a data caching function, but the AIX Virtual Memory Manager caches pages of NFS data just as it caches pages of disk data. If a system is essentially a dedicated NFS server, it may be appropriate to permit the VMM to use as much memory as necessary for data caching. This is accomplished by setting the maxperm parameter, which controls the maximum percentage of memory occupied by file pages, to 100% with:
# vmtune -P 100
The same technique could be used on NFS clients, but would only be appropriate if the clients were running workloads that had very little need for working-segment pages.
NFS uses UDP to perform its network I/O. You should be sure that the tuning techniques described in "TCP and UDP Performance Tuning" and "mbuf Pool Performance Tuning" have been applied. In particular, you should:
In the course of tuning UDP, you may find that the command:
$ netstat -s
shows a significant number of UDP socket buffer overflows. As with ordinary UDP tuning, you should increase the sb_max value. You also need to increase the value of nfs_chars, which specifies the size of the NFS socket buffer. The sequence:
# no -o sb_max=131072 # nfso -o nfs_chars=130000 # stopsrc -s nfsd # startsrc -s nfsd
sets sb_max to a value at least 100 bytes larger than the desired value of nfs_chars, sets nfs_chars to 130972, then stops and restarts the nfsds to put the new values into effect. If you determine that this change improves performance, you should put the no and nfso commands in /etc/rc.nfs, just before the startsrc command that starts the nfsds.
NFS servers that experience high levels of write activity can benefit from configuring the journal logical volume on a separate physical volume from the data volumes. This technique is discussed in "Disk Pre-Installation Guidelines".
The objective of the Prestoserve product is to reduce NFS write latency by providing a faster method than disk I/O of satisfying the NFS requirement for synchronous writes. It provides nonvolatile RAM into which NFS can write data. The data is then considered "safe," and NFS can allow the client to proceed. The data is later written to disk as device availability allows. Ultimately, it is impossible to exceed the long-term bandwidth of the disk, but since much NFS traffic is in bursts, Prestoserve is able to smooth out the workload on the disk with sometimes dramatic performance effects.
This product handles NFS protocol processing on Ethernets, reducing the load on the CPU. NFS protocol processing is particularly onerous on Ethernets because NFS blocks must be broken down to fit within Ethernet's maximum MTU size of 1500 bytes.
Many of the misuses of NFS occur because people don't realize that the files they are accessing are at the other end of an expensive communication path. A few examples we have seen are:
It can be argued that these are valid uses of the transparency provided by NFS. Perhaps so, but these uses cost processor time and LAN bandwidth and degrade response time. When a system configuration involves NFS access as part of the standard pattern of operation, the configuration designers should be prepared to defend the consequent costs with offsetting technical or business advantages, such as:
{kind=link}