If you are sure that you know which resource will limit the speed of your program, you can go directly to the section that discusses appropriate techniques for minimizing the use of that resource. Otherwise, you should assume that the program will be balanced and that all of the recommendations in this chapter may apply. Once the program is implemented, you will want to proceed to "Identifying the Performance-Limiting Resource".
This topic includes the following major sections:
The maximum speed of a truly processor-limited program is determined by:
If the program is CPU-limited simply because it consists almost entirely of numerical computation, obviously the algorithm that has been chosen will have a major effect on the performance of the program. A discussion of alternative algorithms is beyond the scope of this book. It is assumed that computational efficiency has been considered in choosing the algorithm.
Given an algorithm, the only items in the preceding list that the programmer can affect are the source code, the compiler options used, and possibly the data structures. The following sections deal with techniques that can be used to improve the efficiency of an individual program for which the user has the source code. If the source code is not available, tuning or workload-management techniques should be tried.
In "Performance Concepts", we indicated that the RS/6000 processors have a multilevel hierarchy of memory:
As instructions and data move up the hierarchy, they move into storage that is faster than the level below it, but also smaller and more expensive. To obtain the maximum possible performance from a given machine, therefore, the programmer's objective must be to make the most effective use of the available storage at each level.
Effective use of storage means keeping it full of instructions and data that are likely to be used. An obstacle to achieving this objective is the fact that storage is allocated in fixed-length blocks such as cache lines and real memory pages that usually do not correspond to boundaries within programs or data structures. Programs and data structures that are designed without regard to the storage hierarchy often make inefficient use of the storage allocated to them, with adverse performance effects in small or heavily loaded systems.
Taking the storage hierarchy into account does not mean programming for a particular page or cache-line size. It means understanding and adapting to the general principles of efficient programming in a cached or virtual-memory environment. There are repackaging techniques that can yield significant improvements without recoding, and, of course, any new code should be designed with efficient storage use in mind.
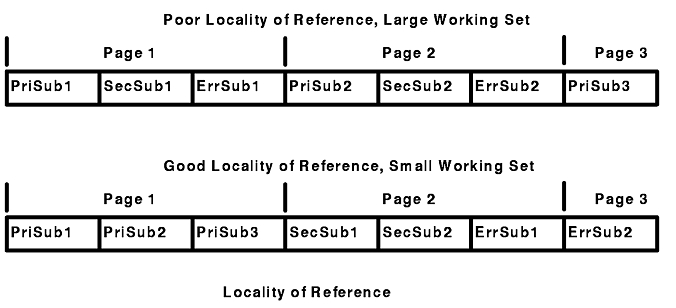
Two terms are essential to any discussion of the efficient use of hierarchical storage: "locality of reference" and "working set. " The locality of reference of a program is the degree to which its instruction-execution addresses and data references are clustered in a small area of storage during a given time interval. The working set of a program during that same interval is the set of storage blocks that are in use, or, more precisely, the code or data that occupy those blocks. A program with good locality of reference will have a minimal working set, since the blocks that are in use are tightly packed with executing code or data. A functionally equivalent program with poor locality of reference will have a larger working set, since more blocks are needed to accommodate the wider range of addresses being accessed.
Since each block takes a significant amount of time to load into a given level of the hierarchy, the objective of efficient programming for a hierarchical-storage system is to design and package code in such a way that the working set remains as small as practical.
The figure "Locality of Reference" illustrates good and bad practice at a subroutine level. The first version of the program is packaged in the sequence in which it was probably written--a sort of programming "stream of consciousness." The first subroutine PriSub1 contains the entry point of the program. It always uses primary subroutines PriSub2 and PriSub3. Some infrequently used functions of the program require secondary subroutines SecSub1 and 2. On very rare occasions, the error subroutines ErrSub1 and 2 are needed. This version of the program has poor locality of reference because it takes three pages of memory to run in the normal case. The secondary and error subroutines separate the main path of the program into three, physically distant sections.
The improved version of the program moves the primary subroutines to be adjacent to one another, puts the low-frequency function next, and leaves the necessary but practically never-used error subroutines to the end of the executable. The most common functions of the program can now be handled with only one disk read and one page of memory instead of the three that were required before.
Remember that locality of reference and working set are defined with respect to time. If a program works in stages, each of which takes a significant time and uses a different set of subroutines, one should try to minimize the working set of each stage.
In general, the allocation and optimization of register space and keeping the pipeline full are the responsibilities of the compilers. The main obligation of the programmer is to avoid structures that defeat compiler-optimization techniques. For example, if you use one of your subroutines in one of the critical loops of your program, it may be appropriate for the compiler to inline that subroutine to minimize execution time. If the subroutine has been packaged in a different .c module, however, it cannot be inlined by the compiler.
Depending on the architecture (POWER, POWER 2, or PowerPC) and model, RS/6000 processors have from one to several caches to hold:
If a cache miss occurs, loading a complete cache line can take a dozen or more processor cycles. If a TLB miss occurs, calculating the virtual-to-real mapping of a page can take several dozen cycles. The exact cost is implementation-dependent. See Appendix C for a more detailed discussion of cache architectures.
Even if a program and its data fit in the caches, the more lines or TLB entries used (that is, the lower the locality of reference), the more CPU cycles it takes to get everything loaded in. Unless the instructions and data are reused many times, the overhead of loading them is a significant fraction of total program execution time, resulting in degraded system performance.
In cached machines, a good style of programming is to keep the main-line, typical-case flow of the program as compact as possible. The main procedure and all of the subroutines it calls frequently should be contiguous. Low-probability conditions, such as obscure errors, should only be tested for in the main line. If the condition actually occurs, its processing should take place in a separate subroutine. All such subroutines should be grouped together at the end of the module. This reduces the probability that low-usage code will take up space in a high-usage cache line. In large modules it is even possible that some or all of the low-usage subroutines may occupy a page that almost never has to be read into memory.
The analogous principle applies to data structures, although it is sometimes necessary to change the code to compensate for the compiler's rules about data layout. An example of this kind of problem was detected during the development of AIX Version 3. Some matrix operations, such as matrix multiplication, involve algorithms that, if coded simplistically, have very poor locality of reference. Matrix operations generally involve accessing the matrix data sequentially, such as row elements acting on column elements. Each compiler has specific rules about the storage layout of matrices. The XL FORTRAN compiler lays out matrices in column-major format (that is, all of the elements of column 1, followed by all the elements of column 2, and so forth) The XL C compiler lays out matrices in row-major format. If the matrices are small, the row and column elements can be contained in the data cache, and the processor and floating-point unit can run at full speed. However, as the size of the matrices increases, the locality of reference of such row/column operations deteriorates to a point where the data can no longer be maintained in the cache. In fact, the natural access pattern of the row/column operations generates a thrashing pattern for the cache where a string of elements accessed is larger than the cache, forcing the initially accessed elements out and then repeating the access pattern again for the same data. The general solution to such matrix access patterns is to partition the operation into blocks, so that multiple operations on the same elements can be performed while they remain in the cache. This general technique is given the name strip mining. A group experienced in numerical analysis was asked to code versions of the matrix-manipulation algorithms that made use of strip mining and other optimization techniques. The result was a 30-fold improvement in matrix-multiplication performance. The tuned routines are in the AIX Basic Linear Algebra Subroutines (BLAS) library, /usr/lib/libblas.a. A larger set of performance-tuned subroutines is the Engineering and Scientific Subroutine Library (ESSL) licensed program, which is documented in the IBM Engineering and Scientific Subroutine Library Guide and Reference.
The functions and interfaces of the Basic Linear Algebra Subroutines are documented in AIX Version 4.3 Technical Reference: Base Operating System and Extensions Volume 2. The FORTRAN run-time environment must be installed to use the library. Users should generally use this library for their matrix and vector operations because its subroutines are tuned to a degree that non-numerical-analyst users are unlikely to achieve by themselves.
If the data structures are under the control of the programmer, other efficiencies are possible. The general principle is to pack frequently used data together whenever possible. If a structure contains frequently accessed control information and occasionally accessed detailed data, make sure that the control information is allocated in consecutive bytes. This will increase the probability that the control information will all be loaded into the cache with a single, or at least with the minimum number of, cache misses.
The programmer who wants to obtain the highest possible performance from a given program running on a given machine must deal with several considerations:
For programmers who lack the time or interest for experiment, there is a simple rule--always optimize. The difference in performance between optimized and unoptimized code is almost always so large that at least basic optimization (the -O option of the cc or xlc or xlf command) should be used as a matter of course. The only exceptions are testing situations in which there is a specific need for straightforward code generation, such as statement-level performance analysis using the tprof tool.
The other techniques yield additional performance improvement for some programs, but the determination of which combination yields the very best performance for a specific program may require considerable recompilation and measurement.
The following sections summarize the techniques for efficient use of the compilers. A much more extensive discussion appears in Optimization and Tuning Guide for XL Fortran, XL C and XL C++.
There are several source-code preprocessors available for the RS/6000. Three with which there is some experience at this time are:
Among the techniques used by these preprocessors is recognition of code that is mathematically equivalent to one of the subroutines in the ESSL or BLAS libraries, mentioned earlier. The preprocessor replaces the original computational code with a call to the corresponding performance-tuned subroutine. Preprocessors also attempt to modify data structures in ways that work more efficiently in RS/6000 machines.
The -qarch compiler option allows you to specify which of the three POWER architectures (POWER, POWER 2, PowerPC) the executable program will be run on. The possible values are:
The -qtune compiler option allows you to give the compiler a hint as to the architecture that should be favored by the compilation. Unlike the -qarch option, -qtune does not result in the generation of architecture-specific instructions. It simply tells the compiler, when there is a choice of techniques, to choose the technique most appropriate for the specified architecture. The possible values for -qtune are:
The figure "Combinations of -qarch and -qtune" shows the valid combinations of values of these options and the default values of -qtune for specified values of -qarch. If neither option is specified, the default is -qarch=COM -qtune=PWR.
In some situations, the optimizer can be inhibited by the need to generate code that is correct in the worst-case situation. The #pragma directive can be used to indicate to the compiler that some constraints can be relaxed, thus permitting more efficient code to be generated.
A pragma is an implementation-defined instruction to the compiler. Pragmas have the general form:
#pragma character_sequence ...
The following pragmas in XL C may have a significant effect on the performance of a program whose source code is otherwise unchanged:
The #pragma disjoint directive lists the identifiers that are not aliases to each other within the scope of their use.
#pragma disjoint ( { identifier | *identifier }
[,{ identifier | *identifier } ] ... )
The directive informs the compiler that none of the identifiers listed shares the same physical storage, which provides more opportunity for optimizations. If any of the identifiers listed do actually share physical storage, the program might produce incorrect results.
The pragma can appear anywhere in the source program. An identifier in the directive must be visible at the point in the program where the pragma appears. The identifiers listed cannot refer to:
The identifiers must be declared before they are used in the pragma. A pointer in the identifier list must not have been used as a function argument before appearing in the directive.
The following example shows the use of the #pragma disjoint directive. Because external pointer ptr_a does not share storage with and never points to the external variable b, the compiler can assume that the assignment of 7 to the object that ptr_a points to will not change the value of b. Likewise, external pointer ptr_b does not share storage with and never points to the external variable a. The compiler can then assume that the argument to another_function has the value 6.
int a, b, *ptr_a, *ptr_b;
#pragma disjoint(*ptr_a, b) /* ptr_a never points to b */
#pragma disjoint(*ptr_b, a) /* ptr_b never points to a */
one_function()
{
b = 6;
*ptr_a = 7; /* Assignment will not change the value of b */
another_function(b); /* Argument "b" has the value 6 */
}
The #pragma isolated_call directive lists functions that do not alter data objects visible at the time of the function call.
#pragma isolated_call ( identifier [ , identifier ] ... )
The pragma must appear before any calls to the functions in the identifier list. The identifiers listed must be declared before they are used in the pragma. Any functions in the identifier list that are called before the pragma is used are not treated as isolated calls. The identifiers must be of type function or a typedef of function.
The pragma informs the compiler that none of the functions listed has side effects. For example, accessing a volatile object, modifying an external object, modifying a file, or calling a function that does any of these can be considered side effects. Essentially, any change in the state of the run-time environment is considered a side effect. Passing function arguments by reference is one side effect that is allowed, but in general, functions with side effects can give incorrect results when listed in #pragma isolated_call directives.
Marking a function as isolated indicates to the optimizer that external and static variables cannot be changed by the called function and that references to storage can be deleted from the calling function where appropriate. Instructions can be reordered with more freedom, which results in fewer pipeline delays and faster execution. Note that instruction reordering might, however, result in code that requires more values of general purpose and/or floating-point registers to be maintained across the isolated call. When the isolated call is not located in a loop, the overhead of saving and restoring extra registers might not be worth the savings that result from deleting the storage references.
Functions specified in the identifier list are permitted to examine external objects and return results that depend on the state of the run-time environment. The functions can also modify the storage pointed to by any pointer arguments passed to the function; that is, calls by reference. Do not specify a function that calls itself or relies on local static storage. Listing such functions in the #pragma isolated_call directive can give unpredictable results.
The following example shows the use of the #pragma isolated_call directive. Because the function this_function does not have side effects, the compiler can assume that a call to it will not change the value of the external variable a. The compiler can then assume that the argument to other_function has the value 6.
int a, this_function(int); /* Assumed to have no side effects */
#pragma isolated_call(this_function)
that_function()
{
a = 6;
this_function(7); /* Call does not change the value of a */
other_function(a); /* Argument "a" has the value 6 */
}
The levels of optimization in the XL compilers have changed from earlier versions. The new levels are:
In the absence of any version of the -O flag, the compiler generates straightforward code with no instruction reordering or other attempt at performance improvement.
These (equivalent) flags cause the compiler to optimize on the basis of conservative assumptions about code reordering. Only explicit relaxations such as the #pragma directives just discussed are used. This level no longer performs software pipelining, loop unrolling, or simple predictive commoning. It also constrains the amount of memory the compiler can use.
The result of these changes is that large or complex routines may have poorer performance when compiled with the -O option than they achieved on earlier versions of the compilers.
Directs the compiler to be aggressive about the optimization techniques used and to use as much memory as necessary for maximum optimization.
This level of optimization may result in functional changes to the program if the program is sensitive to:
These side-effects can be avoided, at some performance cost, by using the -qstrict option in combination with -O3.
The -qhot option, in combination with -O3, enables predictive commoning and some unrolling.
The result of these changes is that large or complex routines should have the same or better performance with the -O3 option (possibly in conjunction with -qstrict or -qhot) that they had with the -O option in earlier versions of the compiler.
AIX provides the ability to embed the string subroutines in the application program rather than using them from libc.a. This saves the Call/Return linkage time. To have the string subroutines embedded, the source code of the application must have the statement:
#include <string.h>
prior to the use of the subroutine(s). In Version 3.1, the only subroutines that would be embedded via this technique were:
Currently, the additional routines are:
If you want to return to the Version 3.1 level of embedding, you should precede the #include <string.h> statement with:
#define __STR31__
In many cases, the performance cost of a C construct is not obvious, and sometimes is even counter-intuitive. The following paragraphs document some of these situations.
In most cases, char and short data items take more instructions to manipulate. The extra instructions cost time, and, except in large arrays, any space that is saved by using the smaller data types is more than offset by the increased size of the executable.
A signed char takes another two instructions more than an unsigned char each time the variable is loaded into a register.
Global variables take more instructions to access than local variables. Also, in the absence of information to the contrary, the compiler assumes that any global variable may have been changed by a subroutine call. This has an adverse effect on optimization because the value of any global variable used after a subroutine call will have to be reloaded.
Unless the global variable is accessed only once, it is more efficient to use the local copy.
Strings use up both data and instruction space. For example, the sequence:
#define situation_1 1 #define situation_2 2 #define situation_3 3 int situation_val; situation_val = situation_2; . . . if (situation_val == situation_1) . . .is much more efficient than:
char situation_val[20]; strcpy(situation_val,"situation_2"); . . . if ((strcmp(situation_val,"situation_1"))==0) . . .
The mem*() family of routines, such as memcpy(), are faster than the corresponding str*() routines, such as strcpy(), because the str*() routines have to check each byte for null and the mem*() routines don't.
In AIX, the C compiler can be invoked by two different commands: cc and xlc. The cc command, which has historically been used to invoke the system's C compiler, causes the XL C compiler to run in langlevel=extended mode. This allows the compilation of existing C programs that are not ANSI-compliant. It also consumes processor time.
If the program being compiled is, in fact, ANSI-compliant, it is more efficient to invoke the XL C compiler via the xlc command.
Use of the -O3 flag implicitly includes the -qmaxmem option. This allows the compiler to use as much memory as necessary for maximum optimization. This can have two effects:
To programmers accustomed to struggling with the addressing limitations of, for instance, the DOS environment, the 256MB virtual memory segments in the RS/6000 environment seem effectively infinite. The programmer is tempted to ignore storage constraints and code for minimum path length and maximum simplicity. Unfortunately, there is a drawback to this attitude. Virtual memory is large, but it is variable-speed. The more memory used, the slower it becomes, and the relationship is not linear. As long as the total amount of virtual storage actually being touched by all programs (that is, the sum of the working sets) is slightly less than the amount of unpinned real memory in the machine, virtual memory performs at about the speed of real memory. As the sum of the working sets of all executing programs passes the number of available page frames, memory performance degrades very rapidly (if VMM memory load control is turned off) by up to two orders of magnitude. When the system reaches this point, it is said to be thrashing. It is spending almost all of its time paging, and no useful work is being done because each process is trying to steal back from other processes the storage necessary to accommodate its working set. If VMM memory load control is active, it can avoid this self-perpetuating thrashing, but at the cost of significantly increased response times.
The degradation caused by inefficient use of memory is much greater than that from inefficient use of the caches because the difference in speed between memory and disk is so much higher than the difference between cache and memory. Where a cache miss can take a few dozen CPU cycles, a page fault typically takes 20 milliseconds or more, which is at least 400,000 CPU cycles.
Although the presence of VMM memory load control in AIX ensures that incipient thrashing situations do not become self-perpetuating, unnecessary page faults still exact a cost in degraded response time and/or reduced throughput.
To minimize the code working set of a program, the general objective is to pack code that is frequently executed into a small area, separating it from infrequently executed code. Specifically:
To minimize the data working set, try to concentrate the frequently used data and avoid unnecessary references to virtual-storage pages. Specifically:
To avoid circularities and time-outs, a small fraction of the system has to be pinned in real memory. For this code and data, the concept of working set is meaningless, since all of the pinned information is in real storage all the time, whether it is used or not. Any program (such as a user-written device driver) that pins code or data must be carefully designed (or scrutinized, if ported) to ensure that only minimal amounts of pinned storage are used. Some cautionary examples are:
{kind=link}
{kind=link}