The Study of Culture.
An introduction to empirical methods
by
Jemeljan Hakemulder
Willie van Peer
Sonia Zyngier
Chapter 6. Experiments
6.1 Introduction
One of the core methods of the Social Sciences is the
experiment. The present chapter will introduce you to the key concepts involved
in this method, and will help you to design your own experiment. In Chapter 3
we discussed the basis of each empirical study: the conceptual model that
describes your hypotheses in terms of the interrelations between variables. In
section 6.2 we will look at the elements that your model comprises: the
relation between the independent variable and the dependent variable, the one
influencing the other. Sections 6.3 through 6.5 will guide you through the
choices you have to make designing your experiment. We will show you how each
choice has its advantages and disadvantages, but also how you can minimize the
effects of the latter. Finally, section 6.6 describes the methodological
problems you need to be aware of will designing your study, but also when
drawing your conclusions. Moreover, this section will be helpful when you are
evaluating the value of previous studies. What it basically comes down to is
this: how certain can you be that your results tell
you something about the relation between independent and dependent variables?
And second, what does this tell you about the world outside our experiment? In
other words, can you generalize your findings beyond the participants of your
study?
6.2 Independent and dependent variables
The purpose
of an experiment is to establish causal relations. You want to examine the
effect of one variable (X) on another (Y). Does narrative perspective in a
story (variable X) affect readers’ identification (variable Y)? Does watching a
horror movie with others (X) cause more excitement (Y) than watching it alone?
Will art education (X) enhance appreciation for abstract paintings (Y)? In all
these examples X is what we call the independent variable and Y the dependent
variable. Degree of identification with a story character, for example, is
assumed to depend on narrative perspective. The independent variable is
the factor that you, as experimenter, manipulate. Hence it is sometimes called
the manipulated factor. In experiments you always try to manipulate some
factor to see whether this causes changes in the dependent variable. For
instance, you write two stories. In one you have an external narrator, and in
the other an internal narrator. In this case your manipulated factor (or
independent variable) is narrative perspective. Another synonym for independent
variables is conditions. In each experiment there is a minimum of two
conditions. For instance: you have one group that reads a story with external
perspective, and one with an internal perspective. Or you have one group of
subjects that watches a horror movie in a group, and one that watches the movie
individually. Sometimes conditions are referred to as levels. In the
last example, the first level is watching the movie in a group; the second is
watching the movie individually.
To help you
realize the range of possible manipulations we will briefly discuss the three
categories of independent variables. (1) In the first you manipulate the
situation. An example of such a situation variable would be having the
participants watch a movie in a group or individually. (2) The second type of
independent variables concerns the tasks you give your participants. Hence,
this type is called task variables. An example would be that one group
of participants is asked to watch one movie, and another group is asked to
watch another. (3) The third type is instruction variables. Participants
in one condition are asked to conduct a certain task in one way, and those in a
second condition are asked to do the same task in another way. In a study by
Zwaan (1991), some participants were told they were to read a newspaper
article. Others were given the same text, but they were told they were to read
a literary text. Zwaan assumed that the different instructions would lead to
different reading styles, that is, either casually skimming the text like most
readers of newspaper articles do, or more carefully paying attention to the
exact wording of the text like readers of literary texts often do. He found
that instructing readers that they were to read literary texts did indeed read
slower and remembered more of the surface structure of the texts than the
participants in the other group that read the exact same texts thinking it were newspaper articles. As you can imagine, in this design
it is essential that Zwaan’s participants were unaware that they were
instructed to do their tasks in different ways.
In some
cases you may want to combine different types of independent variables. In a
study by Bourg et al. (1993), for instance, one instruction variable and one
task variable were examined. Participants were asked to read either story A or
story B (a task variable), and were asked to try to put themselves in the shoes
of the story characters while reading or they were given no specific reading
instruction (instruction variable).
In the
examples we discussed up to now, all independent variables were manipulated. Of
course, you may say, that is the definition of independent variables. However,
in some cases you may want to examine the influence of variables that you cannot
manipulate yourself. For instance, you want to compare females and male
responses to particular television series in which women are the heroines. In
your experiment you have a group of men and a group of women watch an episode
of, for instance, Buffy The Vampier Slayer.
What you are examining in this study is a subject variable rather than a
manipulated variable. The same holds for developmental studies in which the
influence of age is examined. When do children start to realize what is real
and what is fiction in television programs? To test this you may want to
examine three groups: a group of 3-year olds, 6-year olds and 9-year olds. Age
is not a factor that you can manipulate. It is another example of a subject variable.
The
distinction between manipulated variables and subject variables is an important
one. Studies in which you manipulate a factor are called true
experiments. Results of such studies allow you to draw conclusions about cause
and effect. However, when examining subject variables you cannot. Suppose you
find that men identify less with Buffy than women. What causes this
difference? Is it that men dislike women to be the leading protagonist, the one
who saves the day? Or is it that they altogether find it harder to identify
with characters of the opposite sex? Or is it that they, in general, identify
less intense with characters irrespective of gender? The problem illustrated
here is that subject variables do not allow you to control for all variables
that may play a role in your finding. Imagine you are comparing children of
several age groups and you do find a difference. The nine-year-olds can
distinguish reality from fiction, while the three-year olds cannot. Is this
because of a wider experience with television shows, or because of some
cognitive development in the older children?
So
using subject variables makes it harder to generate causal inferences.
Nevertheless, often you will want to compare different groups of participants.
The thing to remember is, then, to be careful in your conclusions. What you can
say is that the groups differed in their scores on the dependent variable. But
you cannot say that this difference was caused by the subject variable.
6.3 Designs
In this
section we will discuss ways to design your study. An experimental design
refers to the sort of comparison you will be making. In some studies you
compare two (or more) groups of participants. For example, in one group you
give participants the instruction that they will see a frightening scene, in another group you do not warn participants. To
assess the effects of forewarning, you ask every participant afterwards how
scary they thought the scene was. This is called a between-subjects design.
You make the comparison between groups of participants (or subjects): on
the one hand, the group of subjects who received the forewarning, on the other
hand the group of subjects who did not. You are interested to find out whether
there is, on the whole a difference between these groups. It will be
clear that in this type of research design it is essential that every person
participates in one group only. If not, you will not be able to examine the
effect of forewarning. In the case of the Zwaan (1991) study mentioned earlier,
we also saw that it was necessary that participants were part of one group
only. They could not both be told that the text they were to read was a
literary text, and be told it was a newspaper article. In these
examples, it is necessary to have naive participants, that is to
say, participants who are unaware of the experimental procedure. When you
examine subject variables you also have no other choice than to have a
between-subject design. For example, comparing responses of two age groups,
participants are per definition part of just one group.
The second
type of design is called within-subject designs. Sometimes participants’
can be submitted to more than one condition. For instance, you have everybody
judge ten paintings. After each time participants are shown a painting they are
asked to rate it on a number of scales. In your analysis you compare the
evaluation of each individual participant of each individual painting. Hence
the term within-subject: you compare two or more measurements within each
individual case. Another term for this type of study is a repeated-measures
design, because you repeatedly measure participants’ evaluation (ten times in
the example). Other examples of within-subject designs are studies that have pretests
and posttests. Vincent van der Velde, one of our students, asked his
participants to rate the reliability of the television news bulletin before and
after they saw a documentary on the personal biases of television journalists.
In his analysis he compared the scores of each individual participant – within
each case – to see whether there were differences between the pretest and the
posttest, hence a within-subject design. To his surprise, he was unable
to register an effect of the documentary on participants’ evaluation of news
bulletins in terms of objectivity and reliability. The choice you make here
determines later, in the analyses of your data, which statistical tests you can
run (see Chapter 9).
Having made
your choice for either a between- or within-subject design, you must now
consider some of the problems involving each of these designs. We will first
look at what issues you should consider when using a
between-subject designs.
Between-subject designs requires equivalent groups
First
let us consider the example of the study examining the effects of forewarning
on arousal. You have a group of participants who are told they will see some
frightening images, and one group is not. As Zillmann et al. (2000) found,
forewarning increases arousal. Anticipating scary images caused more fear than
not expected scary images. Or does it? Maybe in the first group the researchers
had a disproportionate number of people who were not used to seeing frightening
movies, and by coincidence all the horror movie fans in the sample were in the
second group. Would this not affect results? Let us see what results might look
like (see Table 6.1).
|
Forewarning |
|||
|
Without |
With |
||
|
Participant |
Score |
Participant |
Score |
|
P1 |
5 |
P11 |
6 |
|
P2 |
4 |
P12 |
7 |
|
P3 |
6 |
P13 |
1 |
|
P4 |
7 |
P14 |
3 |
|
P5 |
4 |
P15 |
4 |
|
P6 |
4 |
P16 |
7 |
P7 |
1 |
P17 |
6 |
P8 |
2 |
P18 |
5 |
P9 |
3 |
P19 |
5 |
P10 |
1 |
P20 |
3 |
|
Average: |
3,7 |
Average: |
4,7 |
|
Table 6.1. Scariness
scores, with 1=”not scary at all”, and |
|||
|
10=”extremely scary”.
Italics=horror fans |
|||
Clearly the unequal distribution of the horror fans (scores in bold)
makes it hard to compare the two groups. Not having equivalent
groups affected average group results. The (hypothetical) data represented in
Figure 6.2 suggest that being a horror fan decreases scores considerably. Also
notice that this is just one of the many possible confounding factors. Maybe
age plays a role, or gender, or anxiety level prior to the experiment. We do
not know.
One way to
reduce the effect of known and unknown confounding factors is randomization:
participants are assigned to the groups on the basis of coincidence. If you
randomly assign participants to the two groups, there is only a very small
chance that the distribution of horror fans is as unfortunate as shown in Table
6.1. However, randomization is not an absolute guarantee that an equal number
of fans will be in group 1 and group 2. The smaller the number of participants
in each group, the larger the chance that randomization does not result in
equivalent groups.
Therefore,
another way to create equivalent groups is called matching. In this
procedure participants are paired together on some trait known to the
researcher prior to the experiment. An example would be that you have good
reasons to believe, for instance, based on previous research, that frequency of
previous exposure to horror movies influences whether people are frightened by
scary movies. Imagine you want to create two equivalent groups, again to
examine the effects of forewarning. You have participants rate how often they
see movies featuring either chain saw killers, haunted houses, or space monsters.
On each of these items they score from 1 to 10 and the average of the three is
their horror experience score. Subsequently, participants with highly similar
scores are ‘matched’. Here in Figure 6.2 are the hypothetical results for 20
participants.
|
Table 6.2a Calculate
the scores for |
|
Table 6.2b. Arrange
in ascending order; |
||||||
|
preference for scary
movies |
|
|
pair participants and
form two new groups |
|||||
|
Group 1 |
Group 2 |
|
Group 1 |
Group 2 |
||||
|
P1 |
3.6 |
P11 |
1.3 |
|
P3 |
1.3 |
P11 |
1.3 |
|
P2 |
4.7 |
P12 |
1.7 |
|
P12 |
1.7 |
P17 |
2.3 |
|
P3 |
1.3 |
P13 |
5.2 |
|
P15 |
3.1 |
P1 |
3.6 |
|
P4 |
7.3 |
P14 |
4.5 |
|
P18 |
3.8 |
P20 |
4.3 |
|
P5 |
5.6 |
P15 |
3.1 |
|
P14 |
4.5 |
P2 |
4.7 |
|
P6 |
6.8 |
P16 |
7.3 |
|
P13 |
5.2 |
P5 |
5.6 |
|
P7 |
8.1 |
P17 |
2.3 |
|
P6 |
6.8 |
P19 |
6.9 |
|
P8 |
9 |
P18 |
3.8 |
|
P4 |
7.3 |
P16 |
7.3 |
|
P9 |
8.4 |
P19 |
6.9 |
|
P7 |
8.1 |
P9 |
8.4 |
|
P10 |
8.8 |
P20 |
4.3 |
|
P10 |
8.8 |
P8 |
9 |
|
Average |
6.36 |
Average |
4.04 |
|
Average |
5.06 |
Average |
5.34 |
Again the data for the four horror movie fans are printed in italics. As we saw in Table 6.1, the unequal distribution of fans over the two groups messed up the results of the study. Here is what a matching procedure could do to avoid this from happening. In Table 6.2a we can see what scores might look like for the two groups represented earlier in Table 6.1. As you can see, average scores on our scale for experience with horror is higher for the first then for the second group – it may be that this difference explains the difference we saw in Table 6.1. These are the steps you take to form equivalent groups. First you arrange all the scores in ascending order. In the example this would result in the following order: P1, P11, P12, P17, P15, P1, P18, P20, P14, P2, P13, P5, P6, P19, P4, P16, P7,. P9, P10, P8. Second you pair the first in your list with the second (in the example, P3 with P11), the third (P12) with the fourth (P17), and so forth. Now you can create two new groups (see Table 6.2b): the first of each pair is placed in Group 1, and the second in Group 2. As you can see, the horror fans are now equally distributed over the two groups, and the average scary movies preference score is now more or less equal for the two groups (5.06 and 5.34, a mean difference of 0.28). The two groups are now, as to this one variable, more comparable than before (a mean difference of 2.32). Having created two equivalent groups we can now run our experiment testing the effects of forewarning, knowing that our results are not influenced by participants’ experience with horror movies.
As you can
see, the method of matching is more elaborate than that of randomization. It is
the preferred way of creating equivalent groups, however, when the number of
participants you are working with is small. Remember that randomization may not
be effective when working with small samples. Also, use matching when the
variable you want to match participants on affects scores in a predictable way,
for example, the number of academic courses on literature participants’
completed and their ability to detect intertexual references, or children’s age
and the sophistication of the way they recount stories from shows seen on
television. Finally, of course you, can only use
matching when there is a possibility to measure the matching variable.
Practical or organizational reasons may prohibit you to use matching.
Within-Subject designs require control for order effects
When
you have few participants at your disposal and when the tasks that you have in
mind for them cost little time, then repeated measures designs are a suitable
way to conduct your research. Within-subject designs also avoid the equivalent
group problem that between-subject designs have. Your results will not be
influenced here by individual differences among the participants. For instance,
you want to find out whether actors perform better before a large audience than
a smaller one. You ask the actors themselves after their act to rate their performance
and independent researchers rate their performance from footage that does not
reveal the size of the audience. It may be that you find only a few actors who
are willing to participate. In this case it would be opportune to use a
within-subject design: measure the quality of the actors
performance before several audiences of different sizes. Because you measure
more than once, these procedure is also called
repeated-measures design. Another example would be a study in which you want to
find out whether texts describing landscapes are read faster or slower than
those describing action. In this case too you can let your subjects participate
in more than one condition: you ask them to read several passages and measure
their reading pace. Three describe landscapes, and three describe action. You
could also have two groups, one reading the landscape passages and another
group the action passages. However, in this setup you have to make sure your
groups are equivalent. Also, you will need a considerable number of
participants. In a within-subject design you would not have to worry about
differences that may already exist between the groups, for the simple reason
that the participants in all conditions are exactly the same.
Or are
they? After having read, say, five passages participants may be getting tired
of your experiment and read faster anyway, irrespective of the content. As to
the other example mentioned earlier, those actors who expressed their
dissatisfaction with their performance the one night may be more eager to do
better the next, no matter whether the audience is small or large.
These are
called order or sequence effects. The problem is that we do not
know in advance whether such effects will occur, what their direction will be,
or to what extend they will influence the results. In case of the reading
study, maybe participants will read the sixth passage slower because they are
tired, or maybe they will read faster because by then they have fully
“warmed-up.”
As you can
see, every choice in research has its advantages and disadvantages. Every
choice is a matter of give and take. Sometimes your “choices” are dictated by
the purpose of your study or the situation in which you conduct your research.
For instance, when you have very few participants, the choice for a within
subject design is the most obvious one. However, in that case you have to do
everything possible to avoid that sequence effects influence the outcome of
your study. There are several measures that you can take. The first is called complete
counterbalancing. In this procedure every sequence is used only once.
Suppose you want your actors to perform before three different audiences, (A)
one of 20, (B) one of
60, and (C) one of 180 spectators. Because you are not sure how
sequence affects the performances and because you want your results only to
reflect the effect of audience size, and because there are three audience
sizes, you need 3! or 6 actors. The symbol
! stands for the mathematical calculation
called factorial, in which the number preceding the symbol is multiplied by
every number smaller to it until you reach the number 1. 3! for
instance is 3 x 2 x 1 = 6. In the example, participants would be assigned
randomly to one of the following orders:
1. ABC 4.
BAC
2. ACB 5.
CAB
3. BCA 6. CBA
It may be
that actors perform better each consecutive night, due to more training, and
irrespective of audience size. Using just one order, say ABC, this would result
the best scores in audience C, leading you to the dubious conclusion that actors
perform better before large audiences. Using all 6 orders, you know that the
order will not play a role in your final conclusion: the extra effect of
training will contribute equally to all three audience sizes. It could also be
that actors perform worse the second, and even worse the third performance,
maybe due to boredom with their tasks. Again, counterbalancing will eliminate
the possibility that this effect interferes with the purpose of your study:
finding out the effect of audience size on actor performance. Notice that
counterbalancing has an advantage comparable to that of randomization: we do
not need to know which factors may cause an order effect,
neither do we need to know the direction of this effect. The effect will be
“cancelled out” because it will favor each of the conditions to the same
degree.
Now
consider what happens when you want to use complete counterbalancing for the
study in which six passages are read. Remember that you need one participant
for each of the sequences. How many actors would you need? 6! = 6 x 5 x 4 x 3 x
2 x 1 = 720 (!!!) Obviously, when you can only get a few participants complete
counterbalancing is only suitable for experiments with a small number of
conditions. When you have too many conditions to allow for complete
counterbalancing, you can use a subset of the total number of possible
sequences. This is called partial counterbalancing.[1]
What you do is take a random sample of all possibilities.
In the present section
we have discussed two major categories of research designs. In between-subject
designs participants are exposed to one condition only. We have seen that this
type of design requires you to take measures to make equivalent groups. In within-subject
designs, participants are exposed to more than one condition. Here you need to
consider the danger of order effects. Having made your choice for either form
of design you need to make some more. What elements in your design are required
to make your conclusions valid? In other words, which elements are necessary
(or desirable) to infer causal relations between independent and dependent
variables?
6.4 Building an experimental design
The best
way to make your design is to compare the purpose of your own study with what
is called a pretest posttest control group
design. In this design participants are randomized into two groups, one
experimental group, and one control group. Randomization is represented by the
dotted line in the figure below. First both groups make a pretest of
some kind, represented by O1 for the experimental group and O3
for the control group. For the experimental group the pretest is
followed by the treatment (X). They are asked, for instance, to perform some
task like reading a story, seeing a movie, or theater play. Next they are asked
to do the posttest which measures the same variables as the pretest (O2).
The control group is not exposed to any treatment but does do the same posttest
(O4). In the analysis of the results we compare the difference
between O1 and O2 with that of O3 and O4.
The advantage of this design is that there is no reason to assume that extra
experimental factors influence the results. For example, you examine the
effects of a video of a political debate on voters’ behavior; however between
viewing the video (the treatment) and the elections many other factors
may influence your participants. These extra-experimental factors might affect
results of the tests, but there is a good chance they will affect both the
control group and the experimental group scores (see also section 6.6). That is
why having a control group resents such an enormous advantage: because both O2
and O4 are likewise influenced by extra-experimental factors, any difference
between them may be ascribed to X, the experimental treatment.
O1 X O2
- - - - - - - - - - - -
O3 O4
Figure 6.1 Pretest posttest
control group design
An important thing to realize about this so-called classical experimental design is that we do not always need it, that it sometimes is not possible or even desirable to apply it, and finally that sometimes we need to extend on it. For every research question there is at least one design that is most suitable. The purpose of this section is to help you find out which one fits yours best.
We do not always need the full pretest posttest control group design. Let us explain this by using an example. Say we are interested in the effects of the order in which narrative events are presented to readers on their identification with story characters. Intuition may tell us that it makes a difference whether we first meet character A instead of character B; during the rest of the story we may focus a little more on character A’s actions, take his point of view on story events, and identify with him or her. In a study by Bower and colleagues (1978) this hypothesis was examined. They wrote a short story about three characters, Rich, Harry and Cindy. Cindy is to appear in a television commercial for a suntan lotion and she asks her friends Rich and Harry to help her. Harry has to drive a motorboat, and Rich is asked to play the water skier. During the shooting several mishaps occur, but the story is kept intentionally vague about the causes. The researchers write two versions of the story, one that starts with a lead-in of about 300 words about Harry, and one of equal length about Rich. After reading one version of the story participants were asked to fill out a questionnaire registering their recall of feelings for the three characters, their idea about the causes of the mishaps, and their evaluation of the characters. It turned out that in the group that read the version in which they first met Harry, participants tended to locate themselves with Harry and had identified themselves with him. Also on a number of scales they rated Harry more positively than Rich. The accidents were attributed to Rich’s clumsiness. However, in the other group with participants that first read about Rich, the results were exactly the reverse.
In this experimental design we do not see a control group, nor a prestest. Why not? In this study, it is not necessary and not even possible to have either a control group or a pretest. Of course participants who have not read either of the versions can be asked to judge the characters!
Extending on the classical experimental design
In your research you may want to compare several experimental
conditions. In that case you simply add extra experimental groups to the
design. Say you want to compare two conditions. The experimental design would
look like this:
O1 X1 O2
- - - - - - - - - - - - -
O3 X2 O4
- - - - - - - - - - - - -
O5 O6
Figure 6.2 Pretest posttest control group
design with two experimental conditions
For example, when you want to
investigate long-term effects of a treatment one can add a post-posttest (or delayed posttest). For instance, Flerx et
al. (1976) were interested in the possibility of using stories or films
to change children’s ideas about how males and females should behave, in other
words, their sex-role concept. In one experimental condition they read five
stories representing egalitarian roles for male and female characters to a
group of five-year-old readers. In another group children saw five egalitarian
films. Using a pretest-posttest-control-group design they found that both
treatments had an effect on participants’ sex-role concepts. To establish
whether these effects were lasting, they conducted the same posttest one week
after the experiment. Even though difference between control group and
experimental groups became slightly smaller after the seven-day period, the
effects of both treatments were still strong. Considering all the possible
influences that the children may well have experienced between posttest and
post-posttest, this is a remarkable finding. Maybe it may be worthwhile to
include such a delayed posttest in your study too. Often researchers are
satisfied with establishing effects with measures administered right after the
treatment. But in some cases theoretical claims pertain to long-term effects!
To examine some research questions
you may need a design more complicated than the pretest posttest control group
one. For instance, you want to know which of two nature documentaries makes
students more aware of environmental problems. Your independent variable, or
experimental factor, is exposure to one of the two documentaries. But because
you are planning to use the documentaries in an educational setting you want to
find out in which grades which of the two would work best. It may be that the
one has more effect on younger children (e.g., footage of endangered species,
with an emphasis on cute baby animals) and the other may prove to be more fit
for older students (e.g., focusing on the effect of economic growth on the
quality of water and air). To examine this you are planning to compare three
age groups. This is your second experimental factor. You will need six (3 x 2)
groups: three groups per documentary. The design you are using is called a factorial design, and this particular type of factorial design is called a two-way design: There are two factors of interest that are examined, first the
treatment (one of the two documentaries or the control condition) and
participants’ grade.
One can
make things even more complex by adding more factors. In a study by Bourg et
al. (1993) briefly mentioned in section 6.2, we find and example of a three-way design. In their experiment
they examined the effects of empathy on narrative text comprehension.
Participants either got an empathy-building instruction (they were asked to try
to put themselves in the shoes of story characters), or no specific reading
instruction (factor one). They read one of two stories (factor two). Using a
standardized test for reading comprehension, the researchers distinguished
three levels (factor three). After
reading the story several tests to measure story comprehension were
administered. It was found that the empathy-building reading strategy did
indeed enhance comprehension, but only in one story, and that this reading
instruction helped subjects with low comprehension levels more than it did
subjects who had high scores on reading comprehension to begin with. With one
manipulation causing different effects under different conditions we have what
is called an interaction effect. Main
effects are effects of individual factors (or, variables). We speak of an
interaction effect when the effects of one experimental
factor differs with levels of another experimental factor. The procedure
of factorial designs may be the same as for the design we discussed before, nut
the analyses are slightly more complex. This will be explained in Chapter 9.
Doing the
“next best thing”
In some cases it is to be preferred to choose a non-equivalent control group design. As
has been argued earlier, a randomisation procedure allows us to assume that the
groups are more or less comparable, so that any differences in test results are
due to the treatment and not to differences between the groups that already
existed. On the other hand, a randomisation may not always be possible. In field
experiments (that is, an experiment not conducted in a controlled
environment like a ‘laboratory’) one may be forced to work with intact groups,
like classrooms. Moreover, it can be argued that working with intact groups
enhances the ‘naturalness’ of the situation. One problem with experiments is
that they often occur in ‘laboratories’ – it is sometimes contested whether
results that are assessed in these situations can be generalized to real-world
situations. In the case of working with classrooms, students who are taken out
of their classroom environment may become more aware of the test situation and
respond differently compared to when they would all have simply been left in
their class. In large experiments the problem of not being able to randomize
subjects can be solved by working with a number of intact groups and then
randomize these over the conditions, and treat them in the analysis as
individual cases like you would with individual participants. However, realize
that you then need a large number of participants!
6.5 Control groups
The value of experimental research is partly determined by the level of control you have over all sorts of factors that may (or may not!) have played a role in behavioral differences (often: participants’ response to questions) you find between groups. We have seen this in studies that compare participants on subject variables. Because of a lack of control in these studies, we have to be careful in drawing up our conclusions (see section 6.2). Also in studies examining the effects of some type of treatment we have to be aware of alternative explanations for the effect found. Imagine you want to know what effects television advertisements have on people’s self-esteem. You have a series of television ads representing beautiful and successful people, and you expect that watching these ads makes viewers aware of their own shortcomings (not being slim, not having a car, etc.). Or say you want to see what effects reading sessions in the local library have on children’ reading behavior. You expect that being read stories by the librarian once a week for, say, four months will stimulate children to borrow books in the year after the treatment. In this type of studies it is often desirable to have at least two conditions: one in which the treatment is administered, and one in which it is not. The first is then called the experimental group, and the second the control group. These groups are identical in all but one respect: one watches the ads, the other does not; one sits in on the reading sessions, the other does not. The control group provides you with a baseline measure against which you can compare the experimental group. The advantage is that now you can make causal inferences. The difference you find between the groups can only be attributed to the fact that the one did receive a treatment and the other group did not. In other words, there are no alternative explanations.
We distinguish four types of control groups. It is important to consider the choices you have, the advantages of each, and when to apply them. The first is the straight control group. We already saw examples of the use of straight control groups in the previous example. Participants assigned to the control condition simply do not get any treatment. It may be worthwhile for you to consider other possibilities, for example the so-called placebo control group, the second type of control group. In medicine, the term placebo refers to a substance patients believe to have some effect, but in fact is inactive. Imagine you want to find out whether alcohol affects the degree an audience enjoys a comedy show. Your prediction is that alcohol will make the audience laugh louder. However, you also expect that just thinking that you drunk alcohol will make you louder. You want to distinguish this effect from the real effect of alcohol. What you could do is have three groups. One that does not drink alcohol (the straight control group), a second group that you give a certain amount of beer (the experimental group), and a third group that you feed alcohol free beer (the placebo group). Every participant is then equipped with a small device to measure sound output in decibels. Figure 6.2 presents your (fictive) results. Maybe these data may convince you of the use of a placebo group.
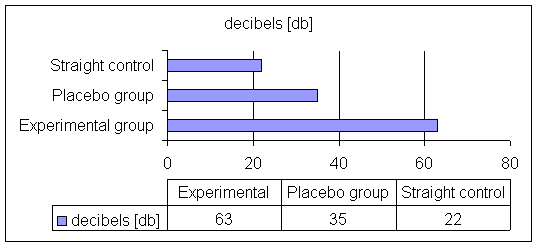
Figure 6.2 Alcohol at the Comedy Club
Participants (in this fictive study) who were unaware that they drank alcohol were louder than the group that drank soft drinks only. What this tells you is that what participants expect about the effects of drinking alcohol already adds to their noisiness (from 22 db to 35 db). However, as you can see, drinking alcohol had an effect that went beyond participants’ expectations about the effects of alcohol (35 db to 63 db). In short, a placebo control group helps you to distinguish the true effect your manipulated variable has from mere suggestion.
The third
type of control group is called waiting list control group. These are
often found in studies evaluating some type of programs. Participants who have not
entered the program yet can function as baseline in the assessment of the
effects of the program. An example would be that you want to examine the
effects of poetry reading on students who suffer from anxiety. You post the
program in your school and 40 students register as participants. You run the
program two times, one time for the first 20 students, and the second time for
the other 20. To assess the effects of the program you could also use students
of your school who did not enter the program. However, these may not be
suffering from anxiety. They may also not have any interest in poetry.
Therefore they are less suitable as control group participants. Better is to
have the second group of students as a waiting list control group, because you
can assume they suffer from the same problems as those of the first group, and
also have the same interest in participating in a program involving reading
poetry.
The fourth
type of control groups is the yoked control group. In such a control
group every participant is paired with (or yoked to) a participant in the
experimental condition. Imagine you are interested in learning effects of
computer games. You study a game for small children to tell the time. What you
are interested in is whether program-generated compliments or reprimands
enhance users’ learning or not. To examine this you have one straight control
group. In this group no program is used. In the experimental group the
participants play the game, and are complimented when they tell the time
correctly, and are reprimanded when they make mistakes. If you find a
difference between the results of the control group and those of the
experimental group, you cannot be sure whether this is due to the rewards and
reprimands. It may be just as well be other aspects of
the game that helped participants to learn. Therefore you need to pair every
participant of the experimental group with a participant who uses a version of
the same game without the compliments and reprimands.
Ending this overview of types of control group now,
you need to decide which would serve the purpose of your study best. The
examples discussed here give you an indication of which type fits which sort of
situations. You have seen that the strength of the claims that you can make on
the basis of your results depends to some degree on your choice. Still there
are a number of other factors that may contribute to the validity of your
conclusions, or that may pose a threat to them.
6.6 Estimating validity
In every
type of research it is important to estimate to what degree the conclusions are
valid. In the present section we will give you an overview of possible threats
to validity, some of general importance, and some specific to evaluating
experimental research. This overview can be used in two ways. First, it may
function as a checklist for you when you are designing your study. Do the
threats apply to your study, and, if so, are there ways to avoid them? Second,
this overview can serve an important role in your literature study. As argued
before in Chapter 3, reviewing the literature will often result in adjusting
and refining your hypotheses. Your literature study will reveal what is
actually known about a certain research problem. To do this, you need to
critically examine claims made by previous researchers about what their
findings mean. Do they offer a solid and acceptable basis for their
interpretation? Did they take care of the threats sufficiently? To enable you
to estimate whether these claims are valid, you obviously need to be aware of what
possible threats there are to validity. Frequently your literature study will
also give you an idea about what the value of your own contribution to the
field can be. Again, one of the factors that you can pay attention to here is
to how your study can improve on what has been done before.
Internal validity
We distinguish two kinds of treats to validity: those
to internal and to external validity. Internal
validity means that the relation we found between our independent and
dependent variable cannot be explained by any other variable. We can be sure
that the results are not due to the interference of some uncontrolled factor.
In some cases researchers do not use a control group, or only conduct a
posttest, or do not apply a randomization procedure. When using such incomplete
experimental design, it is impossible to determine whether differences between
groups are due to the treatment, or to some other difference that was already
there. Take for example this research design:
X O
Figure 6.3 Case study
Here
one group undergoes a treatment. We want to know whether a film studies
education program has an effect on students’ motivation to go see more art
house movies than standard
O1 X O2
Figure 6.4 One-group pretest
posttest design
Imagine
we find an increase in scores from O1 to O2. This design
does not allow us to conclude whether that increase is caused by the program
either. Maybe something else happened during the period of the experiment.
Maybe an art house movie got very popular, like with Being John Malkovich.
We do not know whether scores were influenced by these extra experimental
factors. It could be that we would have registered a more positive attitude
even without the program. Again the internal validity it threatened. To test
this we could use a design like represented in Figure 6.5.
X O1
O2
Figure 6.5
Suppose
that we find a more positive attitude on O1 than on O2. How valid is our conclusion that our
treatment is responsible for this difference? A little more
than before. Now we can tell whether the score of the experimental group
is high or not: we now have a reference point, that is
we can compare scores on O1 with those on O2. However, we
still do not know whether the findings are due to a difference that already
existed between the groups. Maybe participants in the program differ in some
essential respect from our control group participants. They maybe have a
teacher that is particularly interested in art house movies. Hence, maybe there
is a general difference between the curriculum of the experimental group and
that of the control group (which threatens the validity of the study). To test
for such differences we need to conduct pretests:
O1 X O2
O3 O4
Figure 6.6. Non-equivalent control group
design
As you may have noticed, we are now closer to the classical experimental design represented in Figure 6.1, except that Figure 6.6 does not include a randomization procedure. Again we have increased our control over possible intervening variables, and hence the validity. We now know the scores before the experiment and compare them with participants’ scores after the treatment. However, remember our argument on the importance of randomization. Assigning your participants randomly to either experimental or control group will increase your control over the relation between independent and dependent variables. There may be potential variables that may influence the results. We may not be aware of all of these variables. As discussed earlier, randomization may help to avoid this threat to internal validity. As you can see, an incomplete experimental design might cause a lack of control and hence pose a threat to validity, but also remember that in some cases it is impossible to have a perfect design.
Having found ways to restrict the possible influence
of one threat to internal validity (extra-experimental factors), there are
other threats to be considered. First there are the so-called test effects.
Test effects can occur when on doing the pre-test participants learn how to do
the test and consequently perform better on the post-test. For instance, if
they have to do a task in which they have to use some skill, their experience
with the test will help them to do better the second time. Test effects can
also occur when the pretest sensitizes participants to some aspect of the
treatment. Asking participants to fill out a questionnaire on their opinions
about environmental policy before showing them a nature documentary will
probably make them aware of the purpose of the study, and make them focus on
aspects in the documentary related to the questionnaire.
In some studies test effects are avoided by
administering two different tests, hoping that results of both tests can be
compared in that they both measure the same variable. In psychology this is
sometimes done with a Form A and a Form B of the same test (for
instance an IQ test) in with the questions in Form B are put in a
different way compared to Form A. These tests have, ideally, been
calibrated in advance, checking whether they actually do show the same results
for a particular population. However, if the two forms have not been tested in
advance, it is possible that participants respond differently to the wording of
the second test, so that a difference in responses between pre- and post-test
cannot be attributed to the treatment, but is the result of different
formulations in Form A and Form B.
The best way to evaluate the interaction between the
pretest and the treatment is the Solomon design (see Figure 6.7).
O1 X O2
- - - - - -
- - - - - - - - -- - -
O3 O4
- - - - - -
- - - - - - - - - - -
X O5
- - - - - - - - - - - - - -- - -
O6
Figure
6.7 Solomon design
In this
design comparing the differences between O2 and O4 on the
one hand, and O5 and O6 on the other will tell us whether
conducting a pretest influenced the results. In Figure 6.8a we see what results would look like when there is no
interaction between pretest and treatment.
|
Pretest |
|
Posttest |
|
Pretest |
|
Posttest |
|
-3 (O1) |
X |
2 (O2) |
|
-3 (O1) |
X |
2 (O2) |
|
-3 (O3) |
|
-3 (O4) |
|
-3 (O3) |
|
2 (O4) |
|
|
X |
2 (O5) |
|
|
X |
-3 (O5) |
|
|
|
-3 (O6) |
|
|
|
-3 (O6) |
Figure 6.8a No pretest effect Figure 6.8b
Effect of pretest
Comparing
the difference between O2 and O4 and those of O5
and O6 we can conclude that conducting a pretest did not affect the
scores on posttest. In the results presented in Figure 6.8b, however, we see
that filling out a pretest must have influenced scores on the posttest. As you
can see, the Solomon design gives you the possibility to estimate the internal
validity of your study. However, do realize that the procedure involves more
participants. Also, in some cases it will not always be possible to have two
identical treatments, for instance because there is only one group
participating in the art house movie program.
In experiments with a time lapse between pretest
and posttest there is the potential problem of maturation. Maturation refers to the fact that
people change anyway, with or without your treatment. Imagine you want to
measure the effects of a literature program of one year on children’s moral
development. It is likely, however, that children will develop a more advanced
reasoning about moral issues even without the literature program. This problem
is, again, best solved by adding a control group to your design.
Another
problem is formed by the so-called ceiling
or floor effects. Imagine you want to measure the effects of an
advertisement campaign against unsafe sex. In your test you ask “Do you think
it is important to use a condom when you are having sex?” Participants who saw
the ad and control group participants answer this question by indicating their
opinion of a five-point scale.
No,
absolutely not Yes,
absolutely
1 2 3 4 5
In both control group and
experimental group you find extreme high average scores on this scale, say for
instance 4.4 and 4.6 respectively. These findings do not tell you that the
treatment had no effect. It is more likely, however, that, since the control
group also scored high on the test, little could be improved about
participants’ opinions in the first place. Because scores could hardly get any
higher we speak of a ceiling effect (the reverse, with scores not being
able to get any lower, is called a floor effect). A way to avoid this is
to formulate your questions differently, so that you do get a sensitive
instrument to gauge any change that might occur as a result of the treatment.
Also, it is always a good idea to test your instrument in a pilot study, to see
whether the answers to the test could help you distinguish between people with
different opinions on the subject at hand (more on this in the next chapter).
One problem with experiments
involving pretests and posttests is dropouts
(other terms used in the literature are mortality and attrition).
It may happen that between pre-test and post-test some people may decide to
stop participating. If this group of dropouts is a random one this will not be
a thread to internal validity. But there is a chance that you are dealing with
a selection of participants. For instance, in may be that some of your
participants do not like the story of film that you presented to them and
decide not to make the post-test. In experiments were an ability of some kind
is measured it may be that participants who fear they will score low want to
quit.
Let’s say that you are interested in the effects of
poetry reading on anxiety. You do a pretest to select your participants. You
want a group with high scores on anxiety to enrol in a poetry program. After a
week of reading poetry every day you run the same test and find to your
satisfaction a lower score on anxiety. And you conclude that, indeed, reading
poetry can reduce anxiety. Chances are, however, that what you have found is
just a statistical artefact, called regression to the mean. Let us see
how this phenomenon comes about. Imagine you want to select
A last form of internal validity is a special one: statistical
validity. It means that you have chosen the right test for the right data
(remember the levels of measurement discussed in Chapter 5?). How to make the
correct choice will be discussed in Chapter 9.
External validity
External validity means that we have good reasons to believe that our results
can be generalized to the real world. Here we estimate whether our
conclusions are valid for the whole population, that is, for all samples from
that population, in other environments and at other times. Earlier we
considered whether there was indeed a causal relationship between the
manipulated (independent) variable and the variable you measured (dependent
variable) within the experiment. Now we take matters of generalizability into
account: is the causal relationship we found something that we will meet in the
world outside the experiment as well? Will experiments run with other
participants (for instance of a different age group) result in the same
conclusion? Often the steps we take to obtain internal validity results in
threats to external validity. Experiments
are conducted with a selection of people, for instance because we are striving
for group homogeneity. Also, we conduct experiments preferably in controlled
environments (laboratories). As a result, the situation in which we bring
participants is often an artificial one. These measures impair the degree
to which findings can be generalized. Again, we see that conducting
experimental research involves giving and taking. Let us see in what forms we
can run into threats to external validity.
1. First there is the possibility
of an interaction between selection and
treatment/measure: it might be that the group of
participants that you selected you’re your study responds differently to
the treatment or to the test that you administer than another group would. How?
You don’t know. Neither do you know whether this threat does actually occur.
But clearly it poses a problem to the generalizability of your study. One
solution would be to include other groups in a (factorial) design. For
instance, you are interested in how people respond to complexity in paintings.
You ask art students to rate, say, eight selected paintings that you show them
in random order. Before the experiment you asked experts to rate the paintings
on ‘complexity.’ Thus you can arrange them from low complexity (#1) to high
(#8). What you might find is that the higher the complexity of the paintings,
the higher your participants’ aesthetic appreciation. But at some point you may
see that aesthetic appreciation declines with increasing complexity (as
illustrated by the graph below). What is described here in this fictive example
is a recurring result in studies conducted by Berlyne and other researchers.
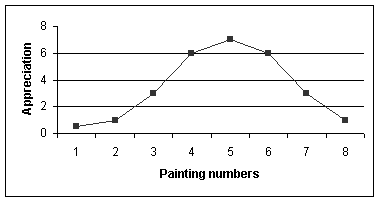
Figure 6.10 Reversed U-curve in
Berlyne’s studies
It may well be, however, that your
results would be different when your respondents had been math students. The
degree of education in art is a likely intervening variable. What you could do
is vary both complexity of the painting and the degree of art education of your
participants by including for instance math students, college freshmen and
graduates in art history. This would certainly enhance the external validity or
generalizability of your findings.
2. A second
threat to external validity is the specific
situation in which the treatment and tests were administered that might
cause an interaction. For instance, it may be that conducting an experiment in
a school, your participants may consider the questionnaire you handed out as a
test. It is possible that in another context they may respond differently. In
other words, here you have a problem generalizing your findings to other
situations.
3. The same
holds for events that occur outside the ‘laboratory’. This threat to external validity
refers to an interaction between treatment and the circumstances outside the
experimental situation. Imagine you are interested in the effects of a
documentary on Islam on viewers’ attitude toward Islamites. But on the moment
you conduct your research, something dramatic happens in world or local
politics that makes participants extra sensitive to your treatment. It seems
likely that in this case you have to be cautious generalizing your findings to
all circumstances.
Note the
similarity with the threat to internal validity mentioned above, that of
extra-experimental events. As you remember, there is a difference: internal
validity refers to the degree to which you can attribute the differences you
found between observations was due to the treatment; external validity refers
to the generalizability of your conclusions.
4. A fourth
tread is an interaction between measurement and treatment. It may be that an
effect of treatment only occurred because you administered a pre-test. One way
to avoid this is the so-called Solomon’s four groups
design, which helps you to determine what exactly caused the effect you
registered.
5. Construct
validity is the last factor that you need to consider. It is often considered
as a special form of external validity. It is here that researchers make
contestable choices. Therefore it is important to examine this possible threat
to validity critically, so as to find out in what way your study can improve on
previous work. Also, in your own study, consider how you yourself ‘translate’
the concepts central to your theory into measurable variables
(operationalization; see Chapter 4).
In this chapter you have learned
how to develop your experiment, and see the weakness and strength of the
various possibilities. Now it is time you run your experiment, collect your
data and enter them into the computer program SPSS (in the next chapter you
will learn how to do this). Then we need to know how to draw conclusions from
your data. First we find out how to explore the data. This requires descriptive
statistics (see Chapter 8). For instance, we may want to know what the group
mean scores on certain variables are. Are they different? And if so, does this
difference tally with our expectations? Often we will need to do more than that
and draw conclusions about causality. For this we need inferential statistics
(Chapter 9 is helpful). Finally, in Chapter 10, we will see how we communicate
our results to fellow researchers in a way they may find useful and
interesting.
References
Bourg, T., K. Risden, S. Thompson and E.C. Davis (1993). The effects of an empathy-building strategy on 6th graders’ causal
inferencing in narrative text comprehension. Poetics 22: 117-133.
Bower
G. H. (1978). Experiments on story comprehension and recall.
Discourse Processes 1: 211-231
Flerx, V.C., D.S. Fidler & R.W. Rogers (1976). Sex role
stereotypes: Developmental aspects and early intervention. Child Development 47: 998-1007.
Goodwin,
C.J. (2002). Research in psychology; Methods and design.
Zwaan, R.A. (1991). Some parameters of literary and news comprehension: Effects of discourse-type perspective on reading rate and surface structure representation. Poetics 20: 139-156.