Abstract
There have been three Text Retrieval Conferences (TREC) organized by the National Institute of Standards and Technology (NIST) over the last three years which have compared retrieval results on fairly large databases (at least 1 gigabyte). The queries (called topics), relevance judgements and databases were all provided by NIST. The main goal of the tests was to compare various retrieval algorithms using various measures of retrieval effectiveness. When Tague-Sutcliffe (in press) performed an analysis of variance on the average precision there is a large group of systems at the top of the ranking which are not significantly different. In addition the queries contribute more to the mean square than the systems. To gather further insight into the results, this research investigates the variation in query properties as a partial explanation for the variation in retrieval scores. For each topic statement for the queries, the length (number of content words), length of various parts and total number of relevant documents are correlated with the average precision.
1. Introduction.
There is a long tradition of information retrieval systems testing using experimental designs dating back to the Cranfield experiments (Cleverdon 1962). The primary purpose of these tests was to show either which indexing methods or which retrieval methods perform the best. The results have usually not been conclusive because of the great number of variables involved and the difficulty of constructing a useful measurement of retrieval effectiveness. Until recently, almost all these retrieval tests were done with relatively small document collections ranging from several hundred to tens of thousands. This still falls short of operational systems with millions of documents. Some notable exceptions are the Blair and Maron (1985) tests and the Medlars tests reported by Lancaster (1968).
2. TREC
To extend retrieval evaluation to larger databases and to a larger number of systems a series of Text Retrieval Conferences (TREC) have been conducted by the United States National Institute of Standards and Technology (NIST) and sponsored by the Advanced Research Projects Agency (ARPA). The first TREC was held in 1992 with 24 participants which is summarized by Harman (1993). The second TREC was held in 1993 (Harman 1994) and the third in 1994. Each of the tests had two different tasks: a routing or filtering operation against new data and an ad-hoc query operation against archival data. For TREC-3 the participants received three gigabytes of data for training the routing algorithms against fifty queries. For the test the routing queries were tested against one gigabyte of new data. For the ad-hoc test there were fifty ad-hoc queries to be tested against two gigabytes of archival data. The TREC-3 data includes evaluations of 42 runs (some participants used more than one method) against the fifty ad-hoc topics and fifty routing topics. The documents used are generally text of some type such as newspaper articles.
3. Previous Retrieval Results
The participants in TREC-3 returned ranked lists of the first 1000 documents retrieved by their systems. The union of all retrieved documents for each query was used as the set of documents to be judged for relevance by an independent set of judges. The total number of relevant documents in this set was used as the basis for judging recall (ratio of relevant-retrieved to total relevant). So in fact the calculated recall is actually a maximum recall. Precision (ratio of relevant-retrieved to total retrieved) was calculated at each rank. Various other measures can then be calculated such as the average precision at standard recall levels (see Salton and McGill 1983). Another measure used throughout is the average precision over all relevant documents retrieved. The precision is calculated after each relevant document is retrieved. If a relevant document is not retrieved, the precision is zero. These precision values are then averaged together to get a single performance number for one system on one query. These values are averaged over all queries to get an average precision for a system. They can also be averaged over systems to get an average performance for a query. They also used R-precision, which is the precision calculated after R documents are retrieved where R is the total number of relevant documents. Another measure used was the precision at standard numbers of documents retrieved, at 5, 10, 15, 20, 30, 100, 200 and 1000.
TREC-1 showed differences in precision and recall values between systems but the question can be asked: "Which differences are significantly different?". Tague-Sutcliffe analyzed the data from TREC-3 with this question in mind. The fifty queries were considered as a random sample from the population of all queries, so that the results can be generalized to any similar sample of queries. In addition to measures mentioned above Tague-Sutcliffe also calculated the precision averaged over the 11 standard recall levels (0.0 to 1.0) and precision averaged over the 9 number of document levels. Using these output measures an analysis of variance was carried out. The model was a repeated measures design, where the runs were performed over the same set of queries:
Yij = µ+Ai+ Bj+Eij
Where Yij is the score for the ith participant on the jth
query,
µ is the overall mean score,
Ai is the effect of the ith run,
Bj is the effect of the jth query,
Eij is the random variation about the mean.
The analysis of variance table for average precision on the ad-hoc data shows that the mean square for the runs (systems) was 0.38 but for the queries was 0.94 (Tague-Sutcliffe, in press, Table 1). Both these values are statistically significant but the variation amongst the queries was much greater than amongst the runs. In addition if a post-hoc Scheffé test is done to see which runs are significantly different, the top 20 runs form a group which are not significantly different from each other, with a range of average precision from 0.42262 to 0.2689. Thus the retrieval tests do not differentiate between systems very well. It seems that some systems do very well on some queries but not on others. The difficult question to answer is "What are the characteristics of the queries and retrieval methods which work well together?". As a preliminary step this research investigates the query characteristics and how they are related to performance measures.
4. Query Characteristics.
Saracevic and Kantor (1988) report on a major study which as a small part, did investigate query characteristics and their effect on recall and precision. They analyzed 40 questions from users where the searching was done by intermediaries on DIALOG databases. The questions were classified on five characteristics by 21 judges. The categories where: domain (subject), clarity, specificity, complexity and presupposition. They found that the number of relevant documents retrieved was higher in questions of low clarity, low specificity, high complexity and many presuppositions. Of these precision was highest in questions of low specificity and high complexity. There were no significant differences in recall levels.
For TREC-3 each participant was given a set of "user needs" statements (called topics) as constructed by users of retrieval systems. They are referred to as "topics" to differentiate the user statements from actual queries constructed by the participants and submitted to the information retrieval systems. For this research the topics from the TREC-3 tests, fifty for routing, fifty for ad-hoc were analyzed by counting the number of content words in total and in the various sections of the topic statement. A stop list of 168 common words was used. The topics for the routing and ad-hoc parts of the test each had different sections (see Appendix 1) recorded in an SGML-like format. For the ad-hoc queries word counts were calculated for the complete query and the title, description and narrative sections. For the routing queries word counts were calculated for the complete query and the title, description, summary, narrative, concepts and definition sections. The statistics provided by the TREC-3 project also included the number of relevant documents for each query and the median (over runs) average precision for the topic. The statistical description of these topics is in Table 1.
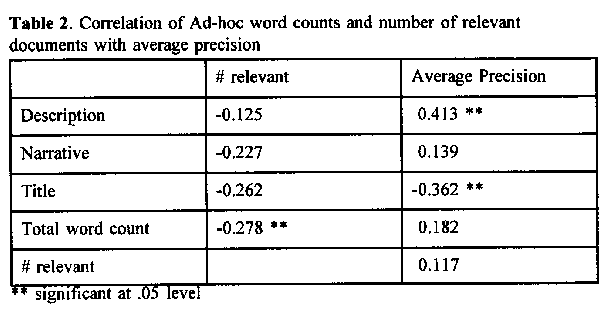
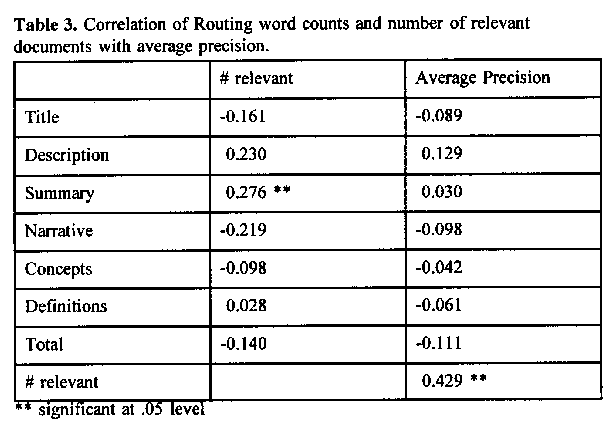
As a first step correlation of the number of relevant documents was correlated with word counts and average precision. The number of relevant documents for a topic is significantly correlated with the average precision in the routing exercise. One possible explanation is that for a topic with a very small number of relevant documents, any method which ranks retrieved documents will eventually have a low precision at high ranks. The number of relevant documents per topic was also slightly negatively correlated with the total number of words in the ad-hoc topic statements. The negative correlation means the longer the topic statement, the smaller the number of relevant documents, but the magnitude of the correlation is fairly small. This may be related to the phenomenon that Saracevic (1988, p.211) reported when he says that the number of relevant documents is greater when the topic is of low clarity and specificity.
Secondly, the correlations of various word counts with the median (over runs) average precision was calculated (Tables 2 and 3). Correlations with average R-precision were also calculated but significant correlations were almost all the same as for precision. This is to be expected because of the high correlation between all the output measures used (Tague-Sutcliffe in press). Looking at the correlations with average precision, we see a significant positive correlation with the "description" part of the ad-hoc topics and a negative correlation with the "title" portion. The titles are generally only a few words long, so it is difficult to explain the correlation, but perhaps the simple topics with short titles are easier to search than long more complicated titles. The description part for the ad-hoc topics is generally only one or two sentences long and describes the type of document being sought. Longer descriptions probably give a better description of the documents which results in better precision. The narrative often adds conditions for relevance to the basic description which often makes the task more complicated, so a longer narrative does not help precision. There were no signigicant correlations of word counts of the routing topics with average precision.
5. Future Work
This work characterizes the topics to some extent, but there needs to some analysis of the relationship between the topics (or queries) and the many characteristics of the retrieval systems used in the various runs. The next step for the topics will be to cluster the queries according to the similarity of performance on the runs. The basic correlation matrix has been calculated and the range of similarities (Pearson's correlation of R-precision) is -0.41 to +0.85 which shows that there are some very different patterns of performance of the topics over the runs. The resulting clusters will have to be explained by referring back to the characteristics of the topics. At the same time the clustering of the runs by the different systems will be carried out.
It may be that the question for large retrieval systems tests should not be "Which retrieval system is the best?" but "Which retrieval methods should be used for this query and this user on this database?". Currently users don't have a choice of retrieval method but can compensate by changing query formulation strategies in different situations.
Table 1. The basic descriptive statistics of these topic characteristics (4K)
References
Blair, D. C., & Maron, M. E. 1985. An Evaluation of Retrieval Effectiveness for a Full-Text Document Retrieval System. Communications of the ACM 28(3): 289-299.
Cleverdon, C. W. 1962. Aslib Cranfield research project: report on testing and analysis of investigation into comparative efficiency of indexing systems. Cranfield, U.K.
Harman, D. 1993. Overview of the first TREC conference. In R. Korfage, & E. Rasmussen (Eds.), Proceedings of the Sixteenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 36-47). Baltimore, MD: ACM.
Harman, D.K. ed. 1994. The second Text REtrieval Conference (TREC-2). Gaithersburg, MD: National Institute of Standards and Technology. (NIST Special Publication 500-215)
Lancaster, F. W. 1968. Interaction Between Requesters and a Large Mechanized Retrieval System. Information Storage Retrieval 4: 239- 252.
Salton, G., & McGill, M. 1983. Introduction to modern information retrieval. New York: McGraw-Hill.
Saracevic, T., & Kantor, P. 1988. A study of information seeking and retrieving. II. Users, questions and effectiveness. Journal of the American Society for Information Science 39(3): 177-196.
Saracevic, T., & Kantor, P. 1988. A study of information seeking and retrieving. III. Searchers, searches and overlap. Journal of the American Society for Information Science 39(3): 197-216.
Saracevic, T., Kantor, P., Chamis, A. Y., & Trivision, D. 1988. A study of information seeking and retrieving. I. Background and methodology. Journal of the American Society for Information Science 39(3): 161- 176.
Tague-Sutcliffe, J. In press. A Statistical Analysis of the TREC-3 Data. In Proceedings of TREC-3 Proceedings (In press).
Appendix 1.
Sample routing query:
Sample ad-hoc query:
{kind=link}
{kind=link}
{kind=link}