This section contains information about multibyte and wide character code subroutines. This section contains the following major subsections:
The internationalized environment of National Language Support blends multibyte and wide character subroutines. The decision of when to use wide character or multibyte subroutines can be made only after careful analysis.
If a program primarily uses multibyte subroutines, it may be necessary to convert the multibyte character codes to wide character codes before certain wide character subroutines can be used. If a program uses wide character subroutines, data may need to be converted to multibyte form when invoking subroutines. Both methods have drawbacks, depending on the program in use and the availability of standard subroutines to perform the required processing. For instance, the wide character display-column-width subroutine has no corresponding standard multibyte subroutine.
If a program can process its characters in multibyte form, this method should be used instead of converting the characters to wide character form.
Attention: The conversion between multibyte and wide character code depends on the current locale setting. Do not exchange wide character codes between two processes, unless you have knowledge that each locale that might used handles wide character codes in a consistent fashion. Most AIX locales use the Unicode character value as a wide character code, except locales based on the IBM-850 and IBM-eucTW codesets.
The following subroutines are used when converting from multibyte code to wide character code:
| mblen | Determines the length of a multibyte character. |
| mbstowcs | Converts a multibyte string to a wide character string. |
| mbtowc | Converts a multibyte character to a wide character. |
The following subroutines are used when converting from wide character code to multibyte character code:
| wcslen | Determines the number of wide characters in a wide character string. |
| wcstombs | Converts a wide character string to a multibyte character string. |
| wctomb | Converts a wide character to a multibyte character. |
main()
{
char *s;
wchar_t wc;
int n;
(void)setlocale(LC_ALL,"");
/*
** s points to the character string that needs to be
** converted to a wide character to be stored in wc.
*/
n = mbtowc(&wc, s, MB_CUR_MAX);
if (n == -1){
/* Error handle */
}
if (n == 0){
/* case of name pointing to null */
}
/*
** wc contains the process code for the multibyte character
** pointed to by s.
*/
}#include <stdlib.h>
#include <limits.h> /* for MB_LEN_MAX */
#include <stdlib.h> /* for wchar_t */
main()
{
char s[MB_LEN_MAX}; /* system wide maximum number of
** bytes in a multibyte character r. */
wchar_t wc;
int n;
(void)setlocale(LC_ALL,"");
/*
** wc is the wide character code to be converted to
** multibyte character code.
*/
n = wctomb(s, wc);
if(n == -1){
/* pwcs does not point to a valid wide character */
}
/*
** n has the number of bytes contained in the multibyte
** character stored in s.
*/
}#include <stdlib.h>
#include <locale.h>
main
{
char *name = "h";
int n;
(void)setlocale(LC_ALL,"");
n = mblen(name, MB_CUR_MAX);
/*
** The count returned in n is the multibyte length.
** It is always less than or equal to the value of
** MB_CUR_MAX in stdlib.h
*/
if(n == -1){
/* Error Handling */
}
}
char buf[]; /* contains the multibyte string */
char *cur, /* points to the current character position */
char *prev, /* points to previous multibyte character */
char *p; /* moving pointer */
/* initialize the buffer and pointers as needed */
/* loop through the buffer until the moving pointer reaches
** the current character position in the buffer, always
** saving the last character position in prev pointer */
p = prev = buf;
/* cur points to a valid character somewhere in buf */
while(p< cur){
prev = p;
if( (i=mblen(p, mbcurmax))<=0){
/* invalid multibyte character or null */
/* You can have a different error handling
** strategy */
p++; /* skip it */
}else {
p += i;
}
}
/* prev will point to the previous character position */
/* Note that if( prev == cur), then it means that there was
** no previous character. Also, if all bytes up to the
** current character are invalid, it will treat them as
** all valid single-byte characters and this may not be what
** you want. One may change this to handle another method of
** error recovery. */#include <stdlib.h>
#include <locale.h>
main()
{
char *s;
wchar_t *pwcs;
size_t retval, n;
(void)setlocale(LC_ALL, "");
n = strlen(s) + 1; /*string length + terminating null */
/* Allocate required wchar array */
pwcs = (wchar_t *)malloc(n * sizeof(wchar_t) );
retval = mbstowcs(pwcs, s, n);
if(retval == -1){
/* Error handle */
}
/*
** pwcs contains the wide character string.
*/
}Note: Processing in this manner will considerably slow down program performance.During the conversion of single-byte code sets, there is no possibility for partial multibytes. However, during the conversion of multibyte code sets, partial multibytes are copied to a save buffer. During the next call to the read subroutine, the partial multibyte is prefixed to the rest of the byte sequence.
Note: A null-terminated wide character string is obtained. Optional error handling can be done if an instance of an invalid byte sequence is found.
#include <stdio.h>
#include <locale.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
char *curp, *cure;
int bytesread, bytestoconvert, leftover;
int invalid_multibyte, mbcnt, wcnt;
wchar_t *pwcs;
wchar_t wbuf[BUFSIZ+1];
char buf[BUFSIZ+1];
char savebuf[MB_LEN_MAX];
size_t mb_cur_max;
int fd;
/*
** MB_LEN_MAX specifies the system wide constant for
** the maximum number of bytes in a multibyte character.
*/
(void)setlocale(LC_ALL, "");
mb_cur_max = MB_CUR_MAX;
fd = open(argv[1], 0);
if(fd < 0){
/* error handle */
}
leftover = 0;
if(mb_cur_max==1){ /* Single byte code sets case */
for(;;){
bytesread = read(fd, buf, BUSIZ);
if(bytesread <= 0)
break;
mbstowcs(wbuf, buf, bytesread+1);
/* Process using the wide character buffer */
}
/* File processed ... */
exit(0); /* End of program */
}else{ /* Multibyte code sets */
leftover = 0;
for(;;) {
if(leftover)
strncpy(buf, savebuf ,leftover);
bytesread=read(fd,buf+leftover, BUFSIZ-leftover);
if(bytesread <= 0)
break;
buf[leftover+bytesread] = '\0';
/* Null terminate string */
invalid_multibyte = 0;
bytestoconvert = leftover+bytesread;
cure= buf+bytestoconvert;
leftover=0;
pwcs = wbuf;
/* Stop processing when invalid mbyte found. */
curp= buf;
for(;curp<cure;){
mbcnt = mbtowc(pwcs,curp, mb_cur_max);
if(mbcnt>0){
curp += mbcnt;
pwcs++;
continue;
}else{
/* More data needed on next read*/
if ( cure-curp<mb_cur_max){
leftover=cure-curp;
strncpy(savebuf,curp,leftover);
/* Null terminate before partial mbyte */
*curp=0;
break;
}else{
/*Invalid multibyte found */
invalid_multibyte =1;
break;
}
}
}
if(invalid_multibyte){ /*error handle */
}
/* Process the wide char buffer */
}
}
}#include <stdlib.h>
#include <locale.h>
main()
{
wchar_t *pwcs; /* Source wide character string */
char *s; /* Destination multibyte character string */
size_t n;
size_t retval;
(void)setlocale(LC_ALL, "");
/*
** Calculate the maximum number of bytes needed to
** store the wide character buffer in multibyte form in the
** current code page and malloc() the appropriate storage,
** including the terminating null.
*/
s = (char *) malloc( wcslen(pwcs) * MB_CUR_MAX + 1 );
retval= wcstombs( s, pwcs, n);
if( retval == -1) {
/* Error handle */
/* s points to the multibyte character string. */
}The majority of wide character classification subroutines are similar to traditional character classification subroutines, except that wide character classification subroutines operate on a wchar_t data type argument passed as a wint_t data type argument.
In the internationalized environment of National Language Support, the ability to create new character class properties is essential. For example, several properties are defined for Japanese characters that are not applicable to the English language. As more languages are supported, a framework enabling applications to deal with a varying number of character properties is needed. The wctype and iswctype subroutines allow handling of character classes in a general fashion. These subroutines are used to allow for both user-defined and language-specific character classes.
The action of wide character classification subroutines is affected by the definitions in the LC_CTYPE category for the current locale.
To create new character classifications for use with the wctype and iswctype subroutines, create a new character class in the LC_CTYPE category and generate the locale using the localedef command. A user application obtains this locale data with the setlocale subroutine. The program can then access the new classification subroutines by using the wctype subroutine to get the wctype_t property handle. It then passes to the iswctype subroutine both the property handle and the wide character code of the character to be tested.
| wctype | Obtains handle for character property classification. |
| iswctype | Tests for character property. |
The isw* subroutines determine various aspects of a standard wide character classification. The isw* subroutines also work with single-byte code sets. The isw* subroutines should be used in preference to the wctype and iswctype subroutines. The wctype and iswctype subroutines should be used only for extended character class properties (for example, Japanese language properties).
When using the wide character functions to convert the case in several blocks of data, the application must convert characters from multibyte to wide character code form. Since this may affect performance in single-byte code set locales, you should consider providing two conversion paths in your application. The traditional path for single-byte code set locales would convert case using the isupper,islower, toupper, and tolower subroutines. The alternate path for multibyte code set locales would convert multibyte characters to wide character code form and convert case using the iswupper, iswlower, towupper and towlower subroutines. When converting multibyte characters to wide character code form, an application needs to handle special cases where a multibyte character may split across successive blocks.
| iswalnum | Tests for alphanumeric character classification. |
| iswalpha | Tests for alphabetic character classification. |
| iswcntrl | Tests for control character classification. |
| iswdigit | Tests for digit character classification. |
| iswgraph | Tests for graphic character classification. |
| iswlower | Tests for lowercase character classification. |
| iswprint | Tests for printable character classification. |
| iswpunct | Tests for punctuation character classification. |
| iswspace | Tests for space character classification. |
| iswupper | Tests for uppercase character classification. |
| iswxdigit | Tests for hexadecimal-digit character classification. |
The following subroutines convert cases for wide characters. The action of wide character case conversion subroutines is affected by the definition in the LC_CTYPE category for the current locale.
| towlower | Converts an uppercase wide character to a lowercase wide character. |
| towupper | Converts a lowercase wide character to an uppercase wide character. |
The following example uses the wctype subroutine to test for the NEW_CLASS character classification:
#include <ctype.h>
#include <locale.h>
#include <stdlib.h>
main()
{
wint_t wc;
int retval;
wctype_t chandle;
(void)setlocale(LC_ALL,"");
/*
** Obtain the character property handle for the NEW_CLASS
** property.
*/
chandle = wctype("NEW_CLASS") ;
if(chandle == (wctype_t)0){
/* Invalid property. Error handle. */
}
/* Let wc be the wide character code for a character */
/* Test if wc has the property of NEW_CLASS */
retval = iswctype( wc, chandle );
if( retval > 0 ) {
/*
** wc has the property NEW_CLASS.
*/
}else if(retval == 0) {
/*
** The character represented by wc does not have the
** property NEW_CLASS.
*/
}
}
When characters are displayed or printed, the number of columns occupied by a character may differ. For example, a Kanji character (Japanese language) may occupy more than one column position. The number of display columns required by each character is part of the National Language Support locale database. The LC_CTYPE category defines the number of columns needed to display a character.
There are no standard multibyte display-column-width subroutines. For portability, convert multibyte codes to wide character codes and use the required wide character display-width subroutines. However, if the __max_disp_width macro (defined in the stdlib.h file) is set to 1 and a single-byte code set is in use, then the display-column widths of all characters (except tabs) in the code set are the same, and are equal to 1. In this case, the strlen (string) subroutine gives the display column width of the specified string. This is demonstrated in the following example:
#include <stdlib.h>
int display_column_width; /* number of display columns */
char *s; /* character string */
....
if((MB_CUR_MAX == 1) && (__max_disp_width == 1)){
display_column_width = strlen(s);
/* s is a string pointer */
}
The following subroutines find the display widths for wide character strings:
| wcswidth | Determines the display width of a wide character string. |
| wcwidth | Determines the display width of a wide character. |
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wint_t wc; int retval; (void)setlocale(LC_ALL, ""); /* ** Let wc be the wide character whose display width is ** to be found. */ retval = wcwidth(wc); if(retval == -1){ /* ** Error handling. Invalid or nonprintable ** wide character in wc. */ } }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs; int retval; size_t n; (void)setlocale(LC_ALL, ""); /* ** Let pwcs point to a wide character null ** terminated string. ** Let n be the number of wide characters ** whose display column width is to be determined. */ retval = wcswidth(pwcs, n); if(retval == -1){ /* ** Error handling. Invalid wide or nonprintable ** character ode encountered in the wide ** character string pwcs. */ } }
Strings can be compared in two ways:
National Language Support (NLS) uses the second method.
Collation is a locale-specific property of characters. A weight is assigned to each character to indicate its relative order for sorting. A character may be assigned more than one weight. Weights are prioritized as primary, secondary, tertiary, and so forth. The maximum number of weights assigned each character is system-defined.
A process inherits the C locale or POSIX locale at its startup time. When the setlocale (LC_ALL, " ") subroutine is called, a process obtains its locale based on the LC_* and LANG environment variables. The following subroutines are affected by the LC_COLLATE category and determine how two strings will be sorted in any given locale.
Note: Collation-based string comparisons take a long time because of the processing involved in obtaining the collation values. Such comparisons should be used only when necessary. If you need to find whether two wide character strings are equal, do not use the wcscoll and wcsxfrm subroutines. Use the wcscmp subroutine instead.
The following subroutines compare multibyte character strings:
| strcoll | Compares the collation weights of multibyte character strings. |
| strxfrm | Converts a multibyte character string to values representing character collation weights. |
The following subroutines compare wide character strings:
| wcscoll | Compares the collation weights of wide character strings. |
| wcsxfrm | Converts a wide character string to values representing character collation weights. |
#include <stdio.h> #include <string.h> #include <locale.h> #include <stdlib.h> extern int errno; main() { wchar_t *pwcs1, *pwcs2; size_t n; (void)setlocale(LC_ALL, ""); /* set it to zero for checking errors on wcscoll */ errno = 0; /* ** Let pwcs1 and pwcs2 be two wide character strings to ** compare. */ n = wcscoll(pwcs1, pwcs2); /* ** If errno is set then it indicates some ** collation error. */ if(errno != 0){ /* error has occurred... handle error ...*/ } }
Note: Determining the size n (where n is a number) of the transformed string, when using the wcsxfrm subroutine, can be accomplished in one of the following ways:
Which method to choose depends on the characteristics of the strings used in the program and the performance objectives of the program.
#include <stdio.h> #include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, *pwcs2, *pwcs3, *pwcs4; size_t n, retval; (void)setlocale(LC_ALL, ""); /* ** Let the string pointed to by pwcs1 and pwcs3 be the ** wide character arrays to store the transformed wide ** character strings. Let the strings pointed to by pwcs2 ** and pwcs4 be the wide character strings to compare based ** on the collation values of the wide characters in these ** strings. ** Let n be large enough (say,BUFSIZ) to transform the two ** wide character strings specified by pwcs2 and pwcs4. ** ** Note: ** In practice, it is best to call wcsxfrm if the wide ** character string is to be compared several times to ** different wide character strings. */ do { retval = wcsxfrm(pwcs1, pwcs2, n); if(retval == (size_t)-1){ /* error has occurred. */ /* Process the error if needed */ break; } if(retval >= n ){ /* ** Increase the value of n and use a bigger buffer pwcs1. */ } }while (retval >= n); do { retval = wcsxfrm(pwcs3, pwcs4, n); if (retval == (size_t)-1){ /* error has occurred. */ /* Process the error if needed */ break; if(retval >= n){ /*Increase the value of n and use a bigger buffer pwcs3.*/ } }while (retval >= n); retval = wcscmp(pwcs1, pwcs3); /* retval has the result */ }
The strcmp and strncmp subroutines determine if the contents of two multibyte strings are equivalent. If your application needs to know how the two strings differ lexically, use the multibyte and wide character string collation subroutines.
The following NLS subroutines compare wide character strings:
| wcscmp | Compares two wide character strings. |
| wcsncmp | Compares a specific number of wide character strings. |
The following example uses the wcscmp subroutine to compare two wide character strings:
#include <string.h>
#include <locale.h>
#include <stdlib.h>
main()
{
wchar_t *pwcs1, *pwcs2;
int retval;
(void)setlocale(LC_ALL, "");
/*
** pwcs1 and pwcs2 point to two wide character
** strings to compare.
*/
retval = wcscmp(pwcs1, pwcs2);
/* pwcs1 contains a copy of the wide character string
** in pwcs2
*/
}
The following NLS subroutines convert wide character strings to double, long, and unsigned long integers:
| wcstod | Converts a wide character string to a double-precision floating point. |
| wcstol | Converts a wide character string to a signed long integer. |
| wcstoul | Converts a wide character string to an unsigned long integer. |
Before calling the wcstod, wcstoul, or wcstol subroutine, the errno global variable must be set to 0. Any error that occurs as a result of calling these subroutines can then be handled correctly.
#include <stdlib.h> #include <locale.h> #include <errno.h> extern int errno; main() { wchar_t *pwcs, *endptr; double retval; (void)setlocale(LC_ALL, ""); /* ** Let pwcs point to a wide character null terminated ** string containing a floating point value. */ errno = 0; /* set errno to zero */ retval = wcstod(pwcs, &endptr); if(errno != 0){ /* errno has changed, so error has occurred */ if(errno == ERANGE){ /* correct value is outside range of ** representable values. Case of overflow ** error */ if((retval == HUGE_VAL) || (retval == -HUGE_VAL)){ /* Error case. Handle accordingly. */ }else if(retval == 0){ /* correct value causes underflow */ /* Handle appropriately */ } } } /* retval contains the double. */ }
#include <stdlib.h> #include <locale.h> #include <errno.h> #include <stdio.h> extern int errno; main() { wchar_t *pwcs, *endptr; long int retval; (void)setlocale(LC_ALL, ""); /* ** Let pwcs point to a wide character null terminated ** string containing a signed long integer value. */ errno = 0; /* set errno to zero */ retval = wcstol(pwcs, &endptr, 0); if(errno != 0){ /* errno has changed, so error has occurred */ if(errno == ERANGE){ /* correct value is outside range of ** representable values. Case of overflow ** error */ if((retval == LONG_MAX) || (retval == LONG_MIN)){ /* Error case. Handle accordingly. */ }else if(errno == EINVAL){ /* The value of base is not supported */ /* Handle appropriately */ } } } /* retval contains the long integer. */ }
#include <stdlib.h> #include <locale.h> #include <errno.h> extern int errno; main() { wchar_t *pwcs, *endptr; unsigned long int retval; (void)setlocale(LC_ALL, ""); /* ** Let pwcs point to a wide character null terminated ** string containing an unsigned long integer value. */ errno = 0; /* set errno to zero */ retval = wcstoul(pwcs, &endptr, 0); if(errno != 0){ /* error has occurred */ if(retval == ULONG_MAX || errno == ERANGE){ /* ** Correct value is outside of ** representable value. Handle appropriately */ }else if(errno == EINVAL){ /* The value of base is not representable */ /* Handle appropriately */ } } /* retval contains the unsigned long integer. */ }
The following NLS subroutines copy wide character strings:
| wcscpy | Copies a wide character string to another wide character string. |
| wcsncpy | Copies a specific number of characters from a wide character string to another wide character string. |
| wcscat | Appends a wide character string to another wide character string. |
| wcsncat | Appends a specific number of characters from a wide character string to another wide character string. |
The following example uses the wcscpy subroutine to copy a wide character string into a wide character array:
#include <string.h> #include <locale.h> #include <stdlib.h>
main()
{
wchar_t *pwcs1, *pwcs2;
size_t n;
(void)setlocale(LC_ALL, "");
/*
** Allocate the required wide character array.
*/
pwcs1 = (wchar_t *)malloc( (wcslen(pwcs2) +1)*sizeof(wchar_t));
wcscpy(pwcs1, pwcs2);
/*
** pwcs1 contains a copy of the wide character string in pwcs2
*/
}
The following NLS subroutines are used to search for wide character strings:
| wcschr | Searches for the first occurrence of a wide character in a wide character string. |
| wcsrchr | Searches for the last occurrence of a wide character in a wide character string. |
| wcspbrk | Searches for the first occurrence of a several wide characters in a wide character string. |
| wcsspn | Determines the number of wide characters in the initial segment of a wide character string. |
| wcscspn | Searches for a wide character string. |
| wcswcs | Searches for the first occurrence of a wide character string within another wide character string. |
| wcstok | Breaks a wide character string into a sequence of separate wide character strings. |
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, wc, *pws; int retval; (void)setlocale(LC_ALL, ""); /* ** Let pwcs1 point to a wide character null terminated string. ** Let wc point to the wide character to search for. ** */ pws = wcschr(pwcs1, wc); if (pws == (wchar_t )NULL ){ /* wc does not occur in pwcs1 */ }else{ /* pws points to the location where wc is found */ } }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, wc, *pws; int retval; (void)setlocale(LC_ALL, ""); /* ** Let pwcs1 point to a wide character null terminated string. ** Let wc point to the wide character to search for. ** */ pws = wcsrchr(pwcs1, wc); if (pws == (wchar_t )NULL ){ /* wc does not occur in pwcs1 */ }else{ /* pws points to the location where wc is found */ } }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, *pwcs2, *pws; (void)setlocale(LC_ALL, ""); /* ** Let pwcs1 point to a wide character null terminated string. ** Let pwcs2 be initialized to the wide character string ** that contains wide characters to search for. */ pws = wcspbrk(pwcs1, pwcs2); if (pws == (wchar_t )NULL ){ /* No wide character from pwcs2 is found in pwcs1 */ }else{ /* pws points to the location where a match is found */ } }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, *pwcs2; size_t count; (void)setlocale(LC_ALL, ""); /* ** Let pwcs1 point to a wide character null terminated string. ** Let pwcs2 be initialized to the wide character string ** that contains wide characters to search for. */ count = wcsspn(pwcs1, pwcs2); /* ** count contains the length of the segment. */ }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, *pwcs2; size_t count; (void)setlocale(LC_ALL, ""); /* ** Let pwcs1 point to a wide character null terminated string. ** Let pwcs2 be initialized to the wide character string ** that contains wide characters to search for. */ count = wcscspn(pwcs1, pwcs2); /* ** count contains the length of the segment consisting ** of characters not in pwcs2. */ }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1, *pwcs2, *pws; (void)setlocale(LC_ALL, ""); /* ** Let pwcs1 point to a wide character null terminated string. ** Let pwcs2 be initialized to the wide character string ** that contains wide characters sequence to locate. */ pws = wcswcs(pwcs1, pwcs2); if (pws == (wchar_t)NULL){ /* wide character sequence pwcs2 is not found in pwcs1 */ }else{ /* ** pws points to the first occurrence of the sequence ** specified by pwcs2 in pwcs1. */ } }
#include <string.h> #include <locale.h> #include <stdlib.h> main() { wchar_t *pwcs1 = L"?a???b,,,#c"; wchar_t *pwcs; (void)setlocale(LC_ALL, ""); pwcs = wcstok(pwcs1, L"?"); /* pws points to the token: L"a" */ pwcs = wcstok((wchar_t *)NULL, L","); /* pws points to the token: L"??b" */ pwcs = wcstok((wchar_t *)NULL, L"#,"); /* pws points to the token: L"c" */ }
NLS provides subroutines for both formatted and unformatted I/O.
Additions to the printf and scanf family of subroutines allow for the formatting of wide characters. The printf and scanf subroutines have two additional format specifiers for wide character handling: %C and %S. The %C and %S format specifiers allow I/O on a wide character and a wide character string, respectively. They are similar to the %c and %s format specifiers, which allow I/O on a multibyte character and string.
The multibyte subroutines accept a multibyte array and output a multibyte array. To convert multibyte output from a multibyte subroutine to a wide character string, use the mbstowcs subroutine.
Unformatted wide character I/O subroutines are used when a program requires code set-independent I/O for characters from multibyte code sets. For example, the fgetwc or getwc subroutine should be used to input a multibyte character. If the program uses the getc subroutine to input a multibyte character, the program must call the getc subroutine once for each byte in the multibyte character.
Wide character input subroutines read multibyte characters from a stream and convert them to wide characters. The conversion is done as if the subroutines call the mbtowc and mbstowcs subroutines.
Wide character output subroutines convert wide characters to multibyte characters and write the result to the stream. The conversion is done as if the subroutines call the wctomb and wcstombs subroutines.
The behavior of wide character I/O subroutines is affected by the LC_CTYPE category of the current locale.
If a program has to go through an entire file that must be handled in wide character code form, it can be done in one of the following ways:
The decision of which one of these methods to use should be made on a per program basis. The second option is recommended, as it is capable of high performance and the program does not have to handle the special cases.
A new data type, wint_t,is required to represent the wide character code value as well as the end-of-file (EOF) marker. For example, consider the case of the fgetwc subroutine, which returns a wide character code value:
Due to these reasons, wint_t data type is needed to represent the fgetwc subroutine return value. The wint_t data type is defined in the wchar.h file.
The following subroutines are used for wide character input:
| fgetwc | Gets next wide character from a stream. |
| fgetws | Gets a string of wide characters from a stream. |
| getwc | Gets next wide character from a stream. |
| getwchar | Gets next wide character from standard input. |
| getws | Gets a string of wide characters from a standard input. |
| ungetwc | Pushes a wide character onto a stream. |
The following subroutines are used for wide character output:
| fputwc | Writes a wide character to an output stream. |
| fputws | Writes a wide character string to an output stream. |
| putwc | Writes a wide character to an output stream. |
| putwchar | Writes a wide character to standard output. |
| putws | Writes a wide character string to standard output. |
#include <stdio.h> #include <locale.h> #include <stdlib.h> main() { wint_t retval; FILE *fp; wchar_t *pwcs; (void)setlocale(LC_ALL, ""); /* ** Open a stream. */ fp = fopen("file", "r"); /* ** Error Handling if fopen was not successful. */ if(fp == NULL){ /* Error handler */ }else{ /* ** pwcs points to a wide character buffer of BUFSIZ. */ while((retval = fgetwc(fp)) != WEOF){ *pwcs++ = (wchar_t)retval; /* break when buffer is full */ } } /* Process the wide characters in the buffer */ }
#include <stdio.h> #include <locale.h> #include <stdlib.h> main() { wint_t retval; FILE *fp; wchar_t *pwcs; (void)setlocale(LC_ALL, ""); index = 0; while((retval = getwchar()) != WEOF){ /* pwcs points to a wide character buffer of BUFSIZ. */ *pwcs++ = (wchar_t)retval; /* break on buffer full */ } /* Process the wide characters in the buffer */ }
#include <stdio.h> #include <locale.h> #include <stdlib.h> main() { wint_t retval; FILE *fp; (void)setlocale(LC_ALL, ""); /* ** Open a stream. */ fp = fopen("file", "r"); /* ** Error Handling if fopen was not successful. */ if(fp == NULL){ /* Error handler */ else{ retval = fgetwc(fp); if(retval != WEOF){ /* ** Peek at the character and return it to the stream. */ retval = ungetwc(retval, fp); if(retval == EOF){ /* Error on ungetwc */ } } } }
#include <stdio.h> #include <locale.h> #include <stdlib.h> main() { FILE *fp; wchar_t *pwcs; (void)setlocale(LC_ALL, ""); /* ** Open a stream. */ fp = fopen("file", "r"); /* ** Error Handling if fopen was not successful. */ if(fp == NULL){ /* Error handler */ }else{ /* pwcs points to wide character buffer of BUFSIZ. */ while(fgetws(pwcs, BUFSIZ, fp) != (wchar_t *)NULL){ /* ** pwcs contains wide characters with null ** termination. */ } } }
#include <stdio.h> #include <locale.h> #include <stdlib.h> main() { int index, len; wint_t retval; FILE *fp; wchar_t *pwcs; (void)setlocale(LC_ALL, ""); /* ** Open a stream. */ fp = fopen("file", "w"); /* ** Error Handling if fopen was not successful. */ if(fp == NULL){ /* Error handler */ }else{ /* Let len indicate number of wide chars to output. ** pwcs points to a wide character buffer of BUFSIZ. */ for(index=0; index < len; index++){ retval = fputwc(*pwcs++, fp); if(retval == WEOF) break; /* write error occurred */ /* errno is set to indicate the error. */ } } }
#include <stdio.h> #include <locale.h> #include <stdlib.h> main() { int retval; FILE *fp; wchar_t *pwcs; (void)setlocale(LC_ALL, ""); /* ** Open a stream. */ fp = fopen("file", "w"); /* ** Error Handling if fopen was not successful. */ if(fp == NULL){ /* Error handler */ }else{ /* ** pwcs points to a wide character string ** to output to fp. */ retval = fputws(pwcs, fp); if(retval == -1){ /* Write error occurred */ /* errno is set to indicate the error */ } } }
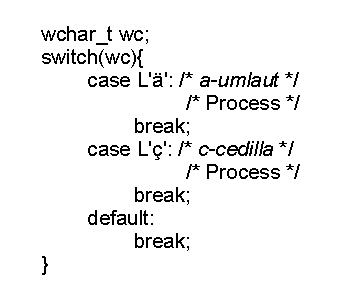
Use the L constant for ASCII characters only. For ASCII characters, the L constant value is numerically the same as the code point value of the character. For example, L'a' is same as a. The reason for using the L constant is to obtain the wchar_t value of an ASCII character for assignment purposes. A wide character constant is introduced by the L specifier. For example:
wchar_t wc = L'x' ;
A wide character code corresponding to the character x is stored in wc. The C compiler converts the character x using the mbtowc or mbstowcs subroutine as appropriate. This conversion to wide characters is based on the current locale setting at compile time. Because ASCII characters are part of all supported code sets and the wide character representation of all ASCII characters is the same in all locales, L'x' results in the same value across all code sets. However, if the character x is non-ASCII, the program may not work when it is run on a different code set than used at compile time. This limitation impacts some programs that use switch statements using the wide character constant representation.
See a partial program example, compiled using the IBM-850 code set.
If this program is compiled and executed on an IBM-850 code set system, it will run correctly. However, if the same executable is run on an ISO8859-1 system, it may not work correctly. The characters a-umlaut and c-cedilla may have different process codes in IBM-850 and ISO8859-1 code sets.
National Language Support Subroutines Overview provides information about wide character and multibyte subroutines.
For general information about internationalizing programs, see National Language Support Overview for Programming and Locale Overview for Programming.
The LC_COLLATE category of the locale definition file in AIX Version 4.3 Files Reference.
The LC_CTYPE category of the locale definition file in AIX Version 4.3 Files Reference.
The localedef command in AIX Version 4.3 Commands Reference, Volume 3
The List of Wide Character Subroutines and
the List of Multibyte
Character Subroutines.
The getc subroutine, printf subroutines, in AIX Version 4.3 Technical Reference: Base Operating System and Extensions Volume 1; and read subroutine, scanf subroutines, setlocale subroutine, strlen subroutine in AIX Version 4.3 Technical Reference: Base Operating System and Extensions Volume 2.
{kind=link}