1. Describe these theories of object perception:
• template approach
• prototype approach
• Pandemonium
• Marr’s approach
• Recognition By Components
2. What are the pros and cons of each theory?
3. What is the basis of the structural description approach?
4. How does Stanley’s vision work? What is the current state of robotic vision in autonomous vehicles?
• ___________: perceiving something as previously experienced
• ______________: naming or classifying an object
How is this done?
• ______-__ (data-driven) processing: low-level stimulus information combined into larger wholes to create representation
• ___-____ (concept-driven) processing: higher-level cognitive processes (e.g., memories, beliefs, expectations) affect interpretations of the stimulus input
- compare input to a model or ________ stored in memory
- stimulus categorized by exact match
Pros & Cons:
![]() successfully used by ________
successfully used by ________
e.g., reading MICR numbers at the bottom of a cheque
![]() cannot handle novel stimuli
cannot handle novel stimuli
![]() cannot handle __________ within a stimulus:
cannot handle __________ within a stimulus:

![]() too many templates required
too many templates required
![]() cannot handle _______:
cannot handle _______:

- individual instances not stored
- represented as prototype: abstraction of _______ or best example of an object
- categorization based on “distance” between perceived item and prototype
Pros & Cons:
![]() more ________ than templates
more ________ than templates
![]() cannot handle _______
cannot handle _______
e.g., Pandemonium (Selfridge, 1959):
Stage 1: “Image Demon” gets sensory input
e.g., R
Stage 2: “Feature Demon” analyze input in terms of ________; each activated by its specific feature
e.g., ![]()
Stage 3: “Cognitive Demon” determine which patterns of features are present, corresponding to known ________
e.g, P R T more than A or X
Stage 4: “Decision Demon” identifies the pattern by listening for the Cognitive Demon shouting the loudest
e.g., “R”
Pros & Cons:
![]() can identify a wide range of stimuli--just specify component features
can identify a wide range of stimuli--just specify component features
![]() feature-detectors physiologically relate to _______ in visual system
feature-detectors physiologically relate to _______ in visual system
![]() doesn’t define “features”
doesn’t define “features”
(two lines forming an angle? single line segment?)
![]() cannot handle ______________ principles (Gestalt laws)
cannot handle ______________ principles (Gestalt laws)
(e.g., when is a row of dots a line?)
![]() cannot handle _______ effects (no “Context Demon”)
cannot handle _______ effects (no “Context Demon”)
![]() cannot be applied to 3-D objects
cannot be applied to 3-D objects
_____-based models:
- these traditional models of visual perception focus on analyzing aspects of the (2-D) retinal image (e.g., junctions, features, etc.)
- they rely on a viewpoint-dependent frame of reference
- as a result, it is difficult to represent a fully 3-D world
__________-description models:
- structural description: a set of symbolic propositions about a particular configuration
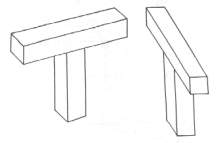
- these are different in the picture domain (2-D) but are the same in the object domain (3-D)
- _____________ among components are important
e.g., brick joined at midpoint to another brick
- problem: defining an object with an ________ frame of reference
- solution: define object’s characteristics with respect to object itself (object-centred)
- determine object’s primary axis using generalized _____
e.g., pyramids, spheres, cylinders, oblongs, as well as “arms” and “legs”
• have an axis of orientation
• a certain location or centre of mass
• overall size
- create shape descriptions of the object at different levels of detail
e.g., human body, limbs, fingers
- each level of hierarchy contains information about:
• axes of cones
• arrangement of axes of component cones (how cones connect)
• internal reference to 3-D description of component models (i.e., “name”)
- this comprises the ___ _____ description
- 3-D model description is object-centred, and thus invariant over changes in position of the viewer
(viewpoint invariance: ability to identify an object from different points of view)
- object identification: finds match between 3-D model description and a stored catalog of known objects
• ___________ index (“level of detail”):
▸ searches through hierarchy of stored information until the information in the 3-D model and in the catalog have the same level of specificity
▸ starts with overall shape information and then goes to more and more specific detail
e.g., object → biped → human → male or female
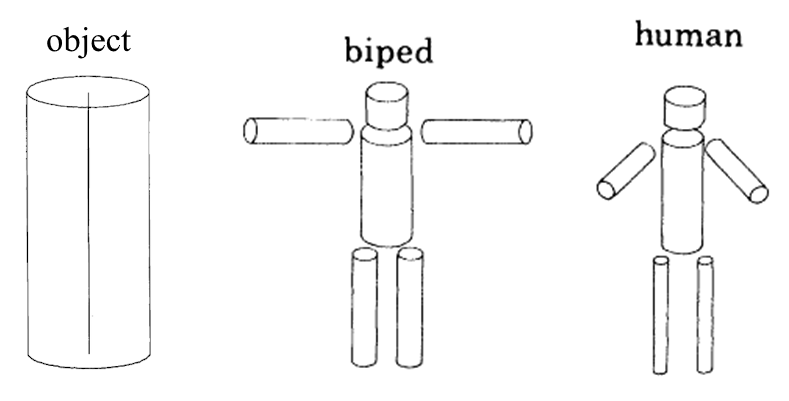
(more detail needed to differentiate David vs. Venus than human vs. tree)
▸ is a bottom-up process because it is based on incoming sensory information, processing generalized cones in terms of how much detail they provide
• _______ (or subcomponent) index (“whole-to-parts reference”):
▸ relates information about components (locations, orientation, relative sizes) to help determine object
e.g., human → arm → forearm → hand → David
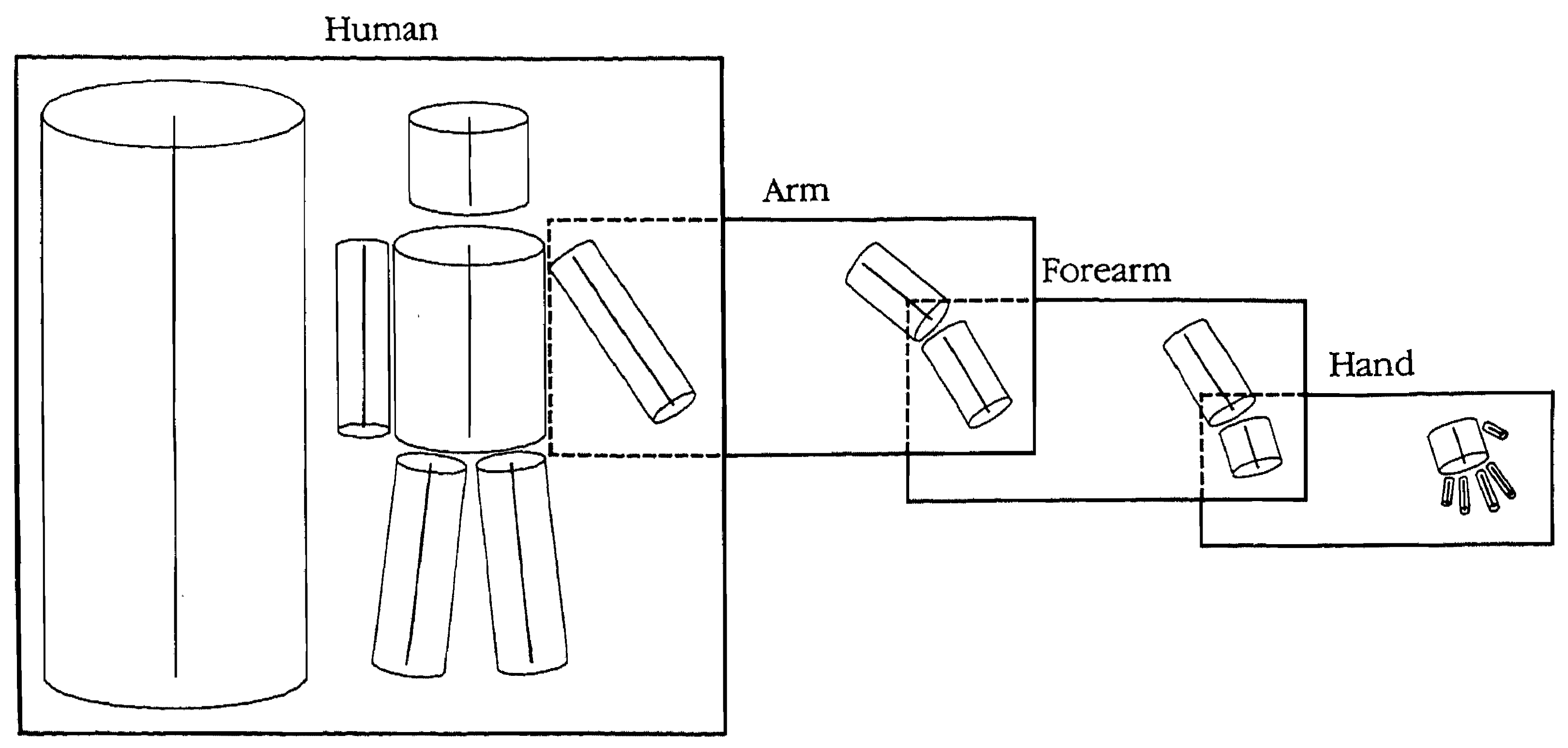
▸ is top-down because of the nature of the information it is using: knowledge of human beings who have arms, that have forearms, that have hands, that belong to certain people
• ______ (or supercomponent) index (“parts-to-whole reference”):
▸ as each component is identified, it provides information on what the whole object is likely to be
e.g., hand → forearm → arm → human → David
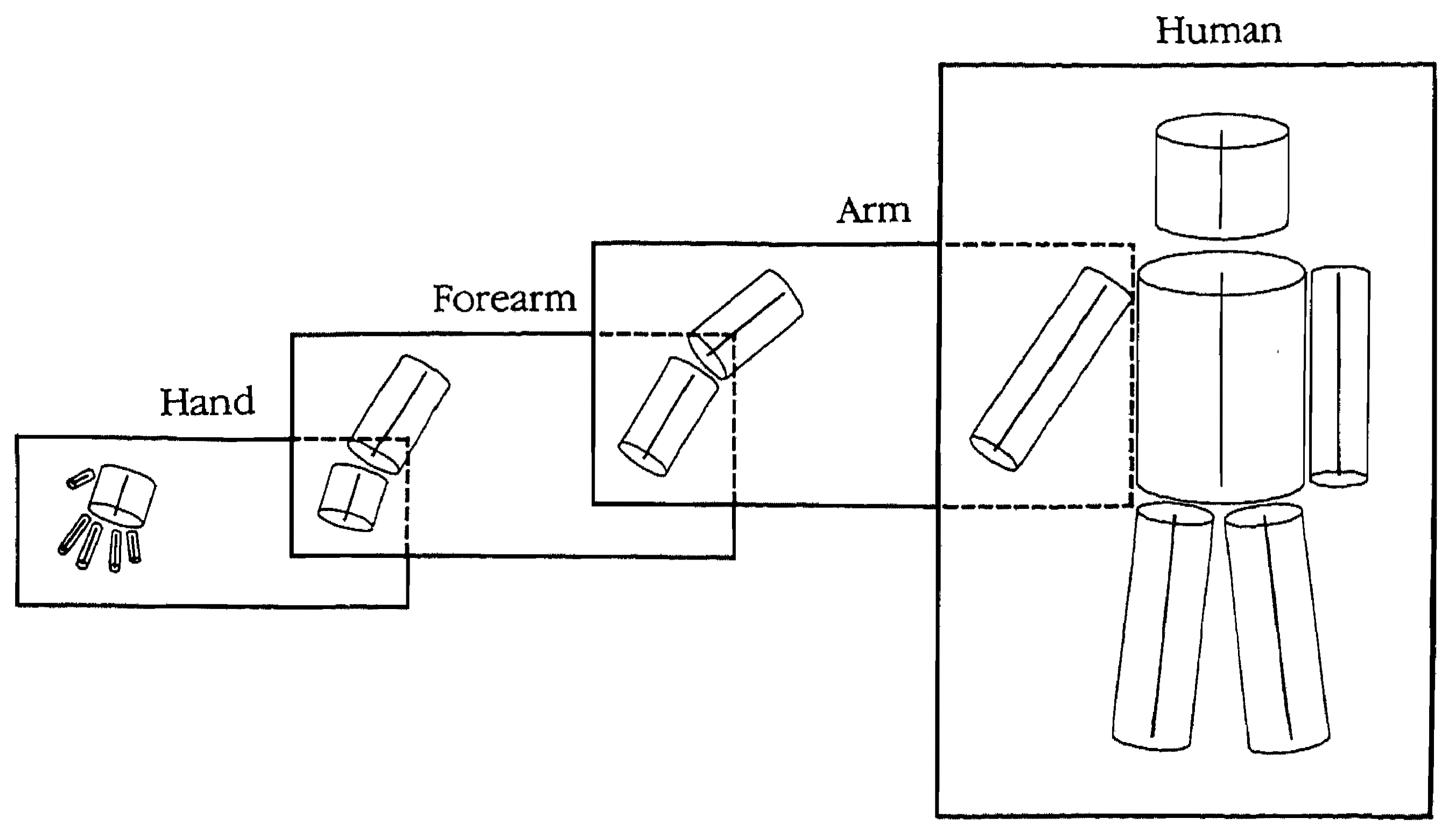
▸ is also top-down because it is also using learned knowledge about objects
Pros & Cons:
![]() doesn’t rely on a list of ________
doesn’t rely on a list of ________
![]() is economical
is economical
![]() handles variation & novel stimuli
handles variation & novel stimuli
![]() allows for top-down processing
allows for top-down processing
![]() accounts for ______________ principles
accounts for ______________ principles
![]() physiological evidence?
physiological evidence?
![]() identifies objects by gross features, not details
identifies objects by gross features, not details
(Biederman, 1987):
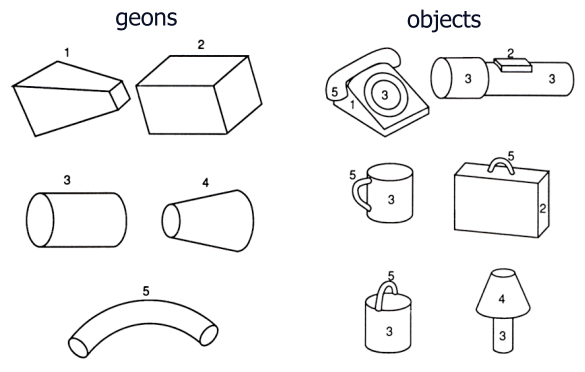
- assumption: visual scene can be decomposed into constant, basic elements
- components called _____ (geometric icons): 36 basic volumetric shapes that can be modified (length, width, etc.), and yet remain identifiable (cylinder, brick, cone):
- different geons have different ___-__________ properties: not an artefact of viewing position, but rather reflect a property of the world
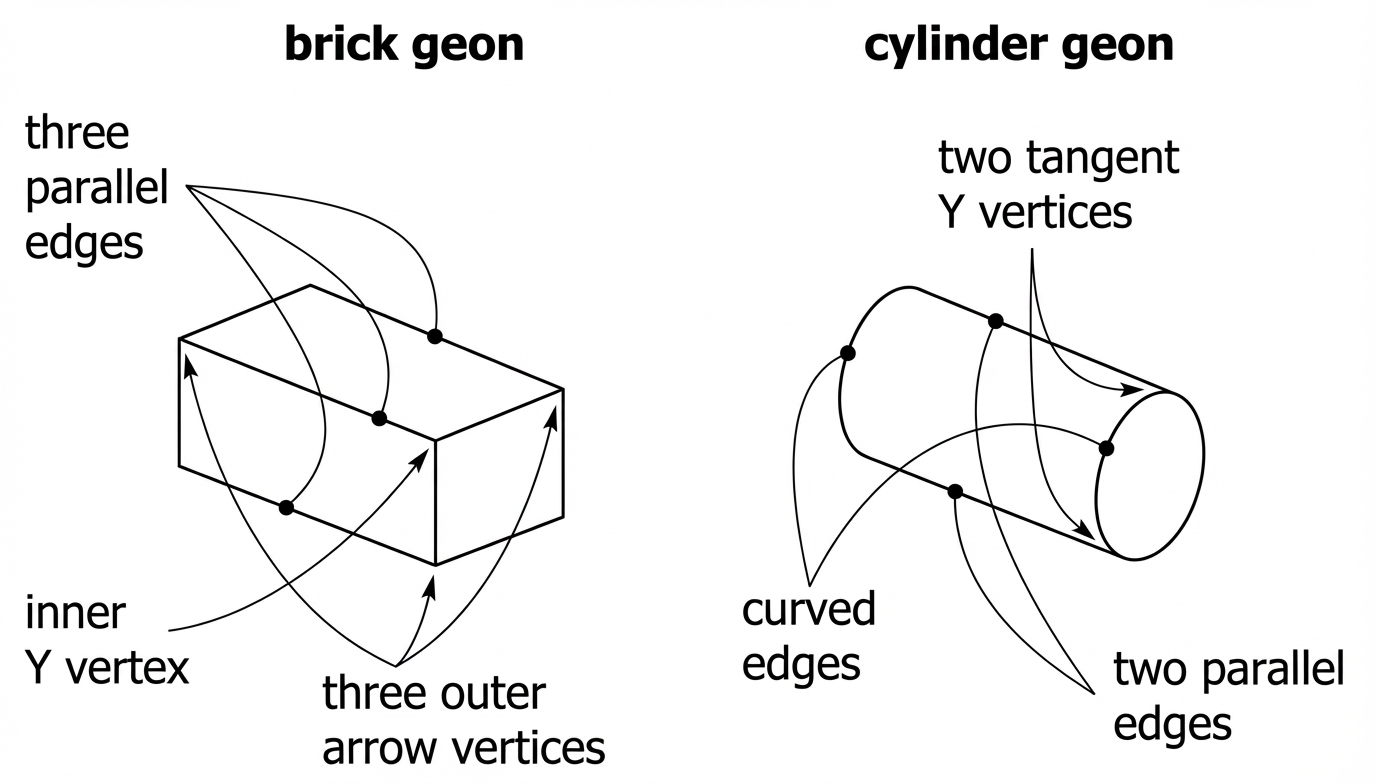
• curvature: curves in the image imply curved edges in the object
e.g., image of sphere is round, because a sphere has a rounded contour
• ____________: straight lines in the image imply straight lines in the object
• symmetry: symmetry in the image implies symmetry in the object
• parallel: parallel lines/curves in the image implies the same in the object
• ______________: lines in the image ending at a common point implies edges of object end at common point
- _________ is important:
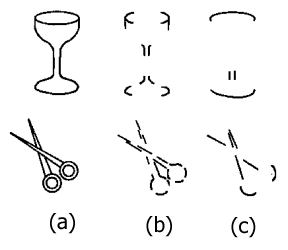
(a) complete stimuli
(b) stimuli preserving concavity information
(c) stimuli lacking concavity information
- Principle of ____________ ________: if an object’s geons can be determined, then the object can be recognized or identified--even if the object is partially obscured
- overview of model:
|
edge extraction |
||||
|
detection of non-accidental properties |
parsing of regions of concavity |
|||
|
determination of components |
||||
|
matching of components to ______ representations |
- evidence: _______ studies (Biederman, 1995)
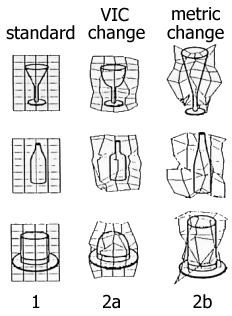
1) prime: present object
e.g., teacup ![]()
2a) viewpoint-invariant contour change: present object from same category made of different geons
e.g., cylindrical mug ![]()
2b) metric change: present object from same category made of same geons, but stretched
e.g., latte bowl ![]()
- responses were ______ for 2b than 2a
Pros & Cons:
![]() has well-defined __________
has well-defined __________
![]() can handle variation & novel stimuli
can handle variation & novel stimuli
![]() is __________
is __________
![]() geons not always reliably determined (e.g., a puddle)
geons not always reliably determined (e.g., a puddle)
![]() may be too broad--objects also differ in their details
may be too broad--objects also differ in their details
![]() is viewpoint-invariant; however, objects are most easily identified from a _________ (or typical) viewpoint
is viewpoint-invariant; however, objects are most easily identified from a _________ (or typical) viewpoint
(the same is true of Marr & Nishihara's model)
(Sebastian Thrun et al., 2006)
DARPA Grand Challenge:
- $1M prize for __________ (self-driving) vehicle completing course up to 270 km long through Mojave desert in no more than 10 hours
- goal: military applications?
- in 2004: none of 15 teams finished; maximum completed was 5%
- in 2005: 23 teams competed over a 212 km course for $2M prize
Stanford University’s Stanley
- based on a turbocharged 4WD 2004 Volkswagen Touareg R5 TDI
- finished _____ in 6 hours, 53 minutes, 58 seconds
Hardware:
- environment sensors:
• 5 _____ (laser imaging, detection, and ranging) range finders (25 m range)
• colour video camera
• 2 radar sensors (200 m range) for detecting large obstacles (not used in race due to technical problems and a lack of large obstacles on the course)
- positioning sensors:
• GPS positioning system
• GPS compass
• inertial measurement unit
- 6 Pentium M computers running Linux
• 1 dedicated to _____ processing
• 2 for all other software
Software:
- environment state consists of multiple ____ (laser, vision, radar)
- these construct 2-D environment map
Vision system:
- lasers can detect obstacles up to 22 m--insufficient range for travel at 55 km/h
- video camera’s effective range: 70 m--but classifying terrain into drivable and non-drivable is __________
- solution: drivable area determined by laser analysis projected into visual image
- _____________ made to similar visual areas out of laser range
e.g., vision initially classifies grass as nondrivable (green area) until lasers scan it (blue trapezoid); lasers conclude grass is drivable; then all grass areas in visual range reclassified as drivable (red area)

- data continually evaluated by a learning algorithm, which can adapt to new terrain
- vision not used to steering control, but for ________ control
Pros and Cons:
![]() showed the power of AI that uses machine learning
showed the power of AI that uses machine learning
![]() fastest autonomous vehicle, by 11 minutes (average 30 km/h)
fastest autonomous vehicle, by 11 minutes (average 30 km/h)
![]() limited obstacle processing (can’t differentiate tall grass vs. _____)
limited obstacle processing (can’t differentiate tall grass vs. _____)
![]() unable to navigate in _______
unable to navigate in _______
![]() little generalizability to _____ vision (weak equivalence)
little generalizability to _____ vision (weak equivalence)
Sequel: DARPA Urban Challenge, 2007
- autonomous vehicles required to obey all traffic regulations, negotiate with other traffic and obstacles, and merge into traffic in a mock urban environment
- 6 (out of 35) teams completed the course
- Stanford Racing Team: “Junior,” a 2006 VW Passat wagon
• 4× Stanley’s computer power
• 360° LIDAR
• 6 cameras for omnidirectional video
• finished in ______ place
- winner: Tartan Racing (CMU/GM): “Boss”
• Waymo autonomous vehicles/robotaxis
- founded by Sebastian Thrun as the Google self-driving car
- autonomously driven over 200 million km
- sensing technology includes LIDAR, radar, and cameras
• Tesla Enhanced Autopilot
- has 8 cameras (up to 250 m range), 12 ultrasonic sensors, and forward-facing radar processed by Tesla Vision neural network
- implicated in over 50 serious __________
• consumer technologies
- autonomous ______ control: adjusts vehicle speed/braking based on data from laser/radar sensors that detect distance to vehicle ahead
e.g., Ford’s Adaptive Cruise Control
- automatic _______: sensors used to aid parallel parking
e.g., Lexus’s Advanced Parking Guidance System
- lane departure warning: signal driver when vehicle moves out of its lane; some systems use computer-processed images from video cameras
e.g., Mercedes-Benz’s Active Lane Keeping Assist
- pre-collision braking and throttle management: slows or stops vehicle if it detects a potentially hazardous object in the way
e.g., Subaru’s EyeSight driver assist technology uses dual cameras
• current technology (Schoettle, 2017):
- no single sensor currently equals human visual perception
- some sensors have capabilities that human drivers do not (e.g., sensing through fog with radar)
- equaling or exceeding human sensing capabilities requires a variety of sensors (e.g., radar, LIDAR, cameras), whose data must be __________ to form a unified representation of the roadway and environment